2018年MCM\ICM的D题探讨了充电桩网络的建设问题,而现阶段的典范之一就是Tesla充电网络了,故需要具体的数据来做可视化,其中主要就是Tesla的充电桩的地理信息,还用到了Google Maps的API对周边地区做搜索
在2023年发现目前已经无法直接使用Python的Request模块简单的请求到Tesla官网的充电桩网页内容,故本文的内容仅为记录用途,无法用于爬取充电桩数据;如果有发现新的方法和无法爬取的具体原因欢迎分享交流
环境
python3环境即可,不过这里可以提的一点是网络环境,大概是我所在的地方访问Tesla的速度比较慢,爬取数据需要几个小时,后面我就把代码放到了Google云上面运行,几分钟就可以跑出结果,而且也不需要特别高的配置,因为这里用到基本的requests和正则匹配
声明:因为个人学识有限,对多线程编程以及减轻对服务器的压力没有做过多的处理,可能会带来一些问题,所以只提供以一种解决问题的思路,顺带贴下的代码,仅供学习研究使用
分析
这里需要的主要是
- 充电桩的位置——经纬度信息
- 充电桩的数目——充电站内的充电桩的数目
要得到这些,联系到之前接触过的东西就是
-
地图的API,通过详细的地名给出经纬度信息
比如说Google MAP API中的Geocoding可以由具体的位置返回一个含有经纬度的Json
-
Tesla官网上的信息
Supercharger中地图右下有View list of location
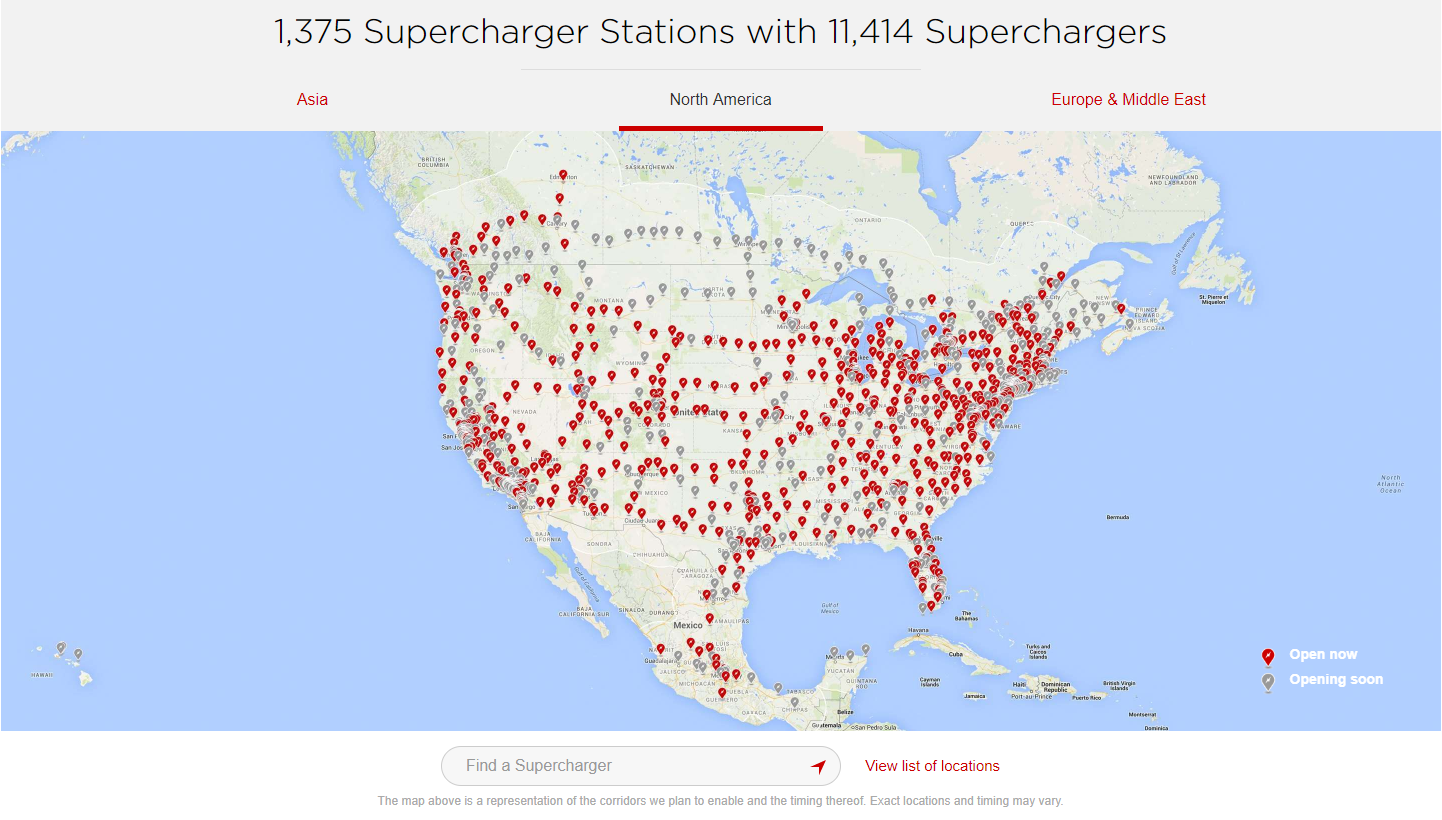
跳转后的网站就给出了美国的充电站的详细位置,那么又如何去获取经纬度呢?
进入某个充电站的详细信息之后就有
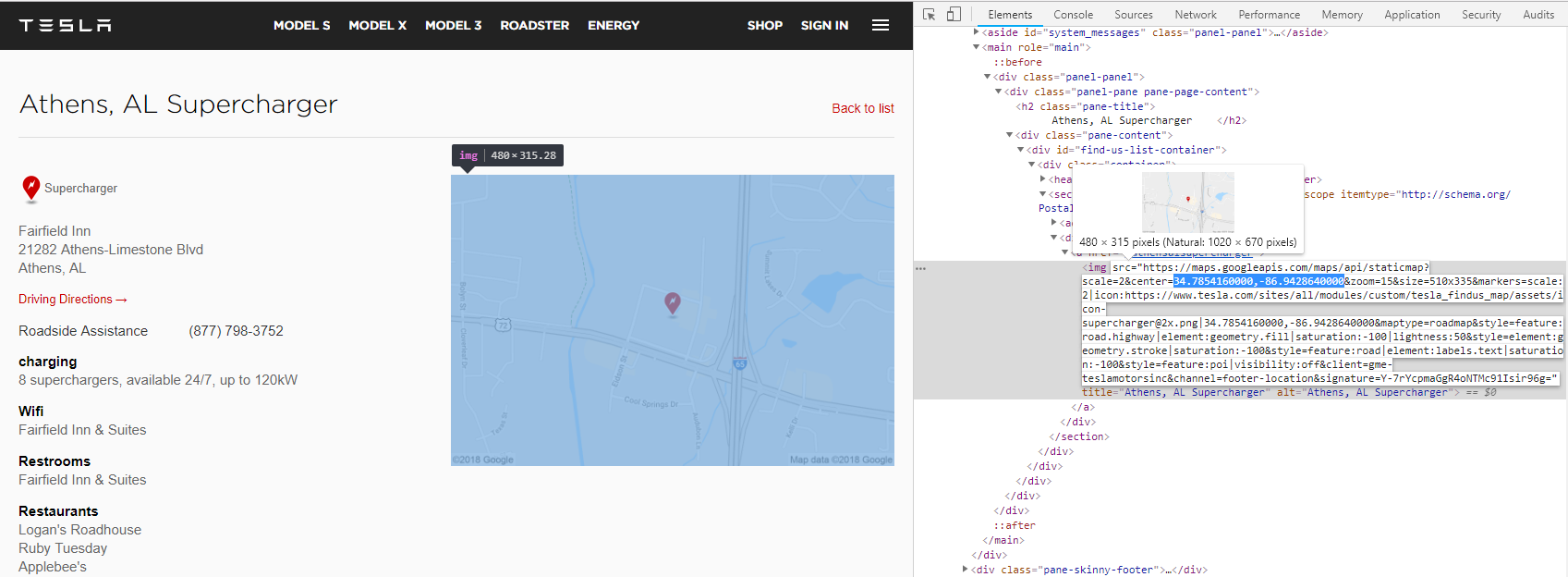
通过浏览器的F12的检查功能就可以看到地图给出了经纬度的信息,另外左侧的文字也给出了充电站内的充电桩的数目,经过这样的分析之后发现,其实只需要做下正则匹配就行了。
…https://maps.googleapis.com/maps/api/staticmap?scale=2¢er=34.7854160000,-86.9428640000&… 这里其实是Google Map的静态地图的API,
代码
这里因为程序是单线程的,索性就把两种充电桩的代码分开写和分开运行了,不同的部分主要是网页url和匹配的规则
Supercharger
#!/usr/bin/env python
# coding=utf-8
import xlwt
import requests
import re
#从Tesla的美国官网获得美国境内的的充电桩位置信息,再由地图导出经纬度信息
BASE_URL="https://www.tesla.com"
LIST_URL="https://www.tesla.com/findus/list"
#chargers or superchargers
CHARER_TYPE="chargers"
#这里需要自己结合网页上的地名修改
REGION="United+States"
filename=REGION+"./tesla_"+CHARER_TYPE+".xls"
region_url = LIST_URL+"/"+CHARER_TYPE+"/"+REGION
data_got = 0
data_error = 0
def get_one_page(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/51.0.2704.63 Safari/537.36'}
response = requests.get(url,headers = headers, timeout = 30)
if response.status_code == 200:
return response.text
else:
print(response.status_code)
return None
except:
print('Requests Error')
return None
#创建表格,添加工作表
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet = book.add_sheet('sheet1',cell_overwrite_ok=True)
#对网页源代码进行匹配
html_region = get_one_page(region_url)
##编译正则匹配对象(就是括号内的部分)
##re.S正则表达式修饰符:使 . 匹配包括换行在内的所有字符
pattern_sub_regions = re.compile('<address.*?<a.*?href="(.*?)".*?>(.*?)</a>.*?</address>',re.S)
##匹配所有的位置条目
suffix_sub_regions = re.findall(pattern_sub_regions,html_region)
#输出形如(/findus/location/charger/dc2789,Benson's Appliance Center)的tuple组成的list
#对匹配的位置条目查询器经纬度信息
for suffix_sub_region in suffix_sub_regions:
sheet.write(data_got,0,suffix_sub_region[1])
url_sub_region = BASE_URL+suffix_sub_region[0]
html_sub_region = get_one_page(url_sub_region)
pattern_location = re.compile('¢er=(.*?)&zoom',re.S)
if CHARER_TYPE=="superchargers":
pattern_chargers = re.compile('<p><strong>[Cc]harging</strong>.*?>(.*?) [Ss]uperchargers.*?</p>',re.S)
if CHARER_TYPE=="chargers":
pattern_chargers = re.compile('<p><strong>[Cc]harging</strong>.*?>(.*?)Tesla.*?</p>',re.S)
try:
location = re.findall(pattern_location,html_sub_region) ##输出经纬度的list
sheet.write(data_got,1,location[0])
except:
print('Error',data_error,':',url_sub_region)
data_error+=1
try:
chargers = re.findall(pattern_chargers,html_sub_region) ##输出充电桩的个数
sheet.write(data_got,2,chargers[0])
except:
chargers = ['0']
sheet.write(data_got,2,'0')
print(data_got,':',suffix_sub_region[1],location[0],chargers[0])
data_got+=1
#直接把结果保存在当前目录下的xls文件里面
book.save(filename)
print('Finished,totally got %d Charging Station,and %d Error'% (data_got,data_error))
结果
程序大概要跑几分钟,爬下来的数据大概是4000+条,最后在Google MAP画出来就是下面这样, 这里也把即将建成的充电站画了进来,不过该充电站下属的充电桩数目为0
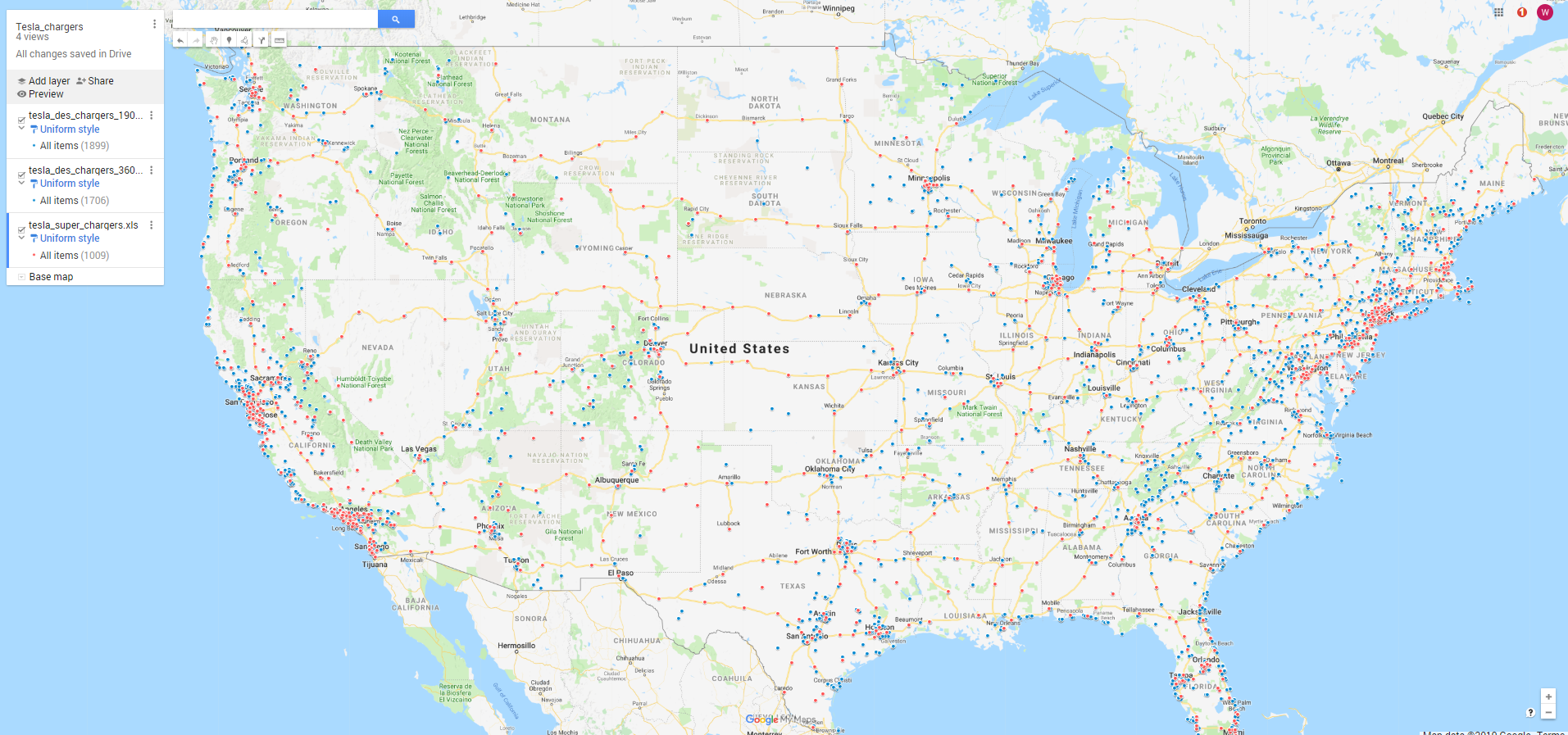
其中Super Chargers为蓝色,Destination Chargers为红色
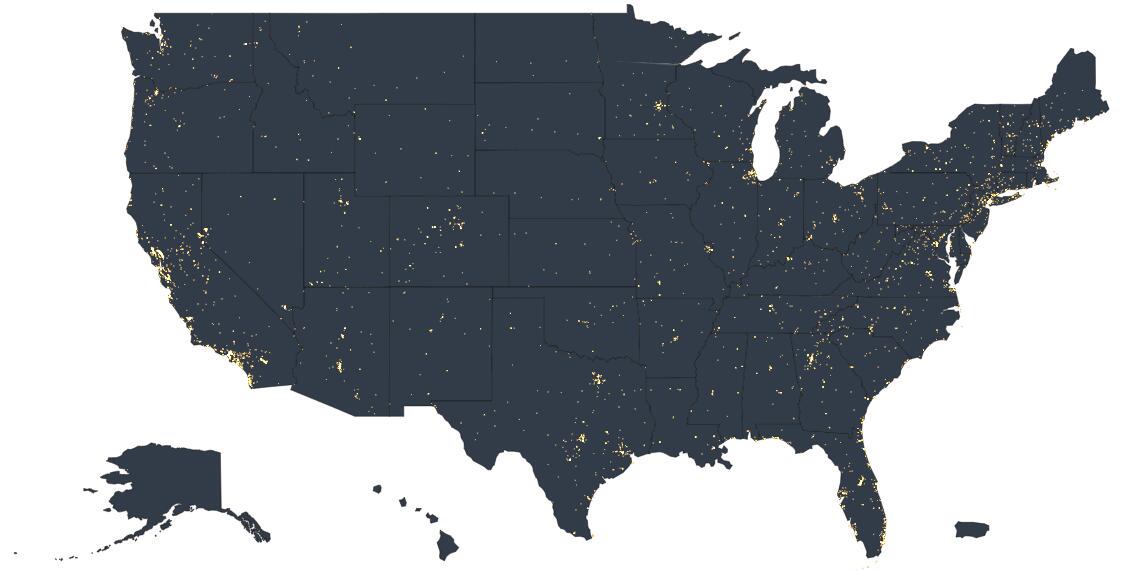
ECharts.js可视化
这里用了下ScatterGL,点的数量不多,但是可以看出密度越高的部分也就越亮
附近搜索功能
常用的一个功能:返回一个地点的周围的搜索结果,可以用Google Map的API实现,这里用的是Python的googlemaps库 详细的使用方法可见:reference documentation
需要注意的地方:
-
每次搜索返回二十个结果,但是可以翻页,最多返回六十个结果
-
翻页的速度不能太快,所以这里在使用token的时候sleep了3秒
-
默认的搜索结果是按推荐排序的,有选项可以按照距离排序
import googlemaps
import xlwt
import time
TYPE='restaurant'
KEYWORK='food'
filename="./near_by_"+TYPE+".xls"
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet = book.add_sheet('sheet1',cell_overwrite_ok=True)
gmaps = googlemaps.Client(key='YOUR_API_KEY')
near_json=gmaps.places_nearby(location='34.0664817,-118.3520389',radius='50000',type=TYPE,keyword=KEYWORK)
list_results=near_json['results']
next_page_token=near_json['next_page_token']
time.sleep(3)
next_json=gmaps.places_nearby(page_token=next_page_token)
time.sleep(3)
list_results.extend(next_json['results'])
next_page_token=next_json['next_page_token']
nxet_json=gmaps.places_nearby(page_token=next_page_token)
list_results.extend(next_json['results'])
list_loc=[]
sheet.write(0,0,'lat&lng')
i=1
for result in list_results:
str_temp=str(result['geometry']['location']['lat'])+','+str(result['geometry']['location']['lng'])
list_loc.append(str_temp)
sheet.write(i,0,str_temp)
i+=1
book.save(filename)
推一下舍友的工作
Equations.online上面是从北汽爬取的数据,复杂度更高,数据量也要大很多