因为流量限制比较致命,所以经常查流量,苦于需要经常输入验证码,所以就写了一个Python脚本,还发现了一些有趣的问题;另外扩充了下移动运营商的流量查询和iOS小组件显示
Update:这次又是在手机端发现了不需要验证码的登陆方法,本来重点是在实现简单的验证码识别,之后再是进一步提高识别准确率和查询速度,所以..如果想要用的话直接找代码好了:xidian_script仓库
校园网流量查询脚本
这是针对西安电子科技大学校园网流量查询网站写的一个查询程序,主要解决了以下问题:
- 支持命令行运行,无需读写额外的文件
- 自动识别和输入验证码
环境
Python:Python3,Python2下编码可能有问题
网络:学校内网
如果是外网的话需要换个地址(换了外网就是HTTPS加密了~)
依赖
系统:推荐在Linux环境下运行(比如说WSL),速度更快,安装也更方便
Python库:
import sys
import requests
import pytesseract
import prettytable as pt
from lxml import html
from lxml import etree
from PIL import Image
from io import BytesIO
其中,pytesseract需要下面的Tesseract才能够正常使用,另外cssselect可能需要单独安装
Tesseract
Tesseract 是一个 OCR(Optical Character Recognition,光学字符识别)引擎,能够识别图片中字符
Github 地址:tesseract-ocr/tesseract
Linux:Github上有说明,一般使用系统自带的包管理安装就好
Windows:推荐使用包管理软件,如Scoop
scoop install tesseracet
如果不使用包管理的话比较麻烦,参考下面的教程设置,主要是环境变量
Windows安装Tesseract-OCR 4.00并配置环境变量
安装完成之后,在命令行键入tesseract得到软件提示说明安装成功
使用方法
基本的使用就是修改代码中的账户名和密码,然后运行代码即可,最终的效果如下:

注:有时候因为验证码识别失败次数太多,需要重新运行,默认的失败次数阈值下,出现这种情况的概率小于千分之一,平均运行时间在2s左右,如果有其他需求,根据代码提供的接口改下就好
实现方法
简单的说下原理,主要是模拟流量查询部分的登陆,最为关键的是cookies,另外使用XPath简化匹配
对网页登陆的过程分析
工具
这里用的Chrome浏览器的检查功能(F12),之后进入Network选项卡,勾选preserve log
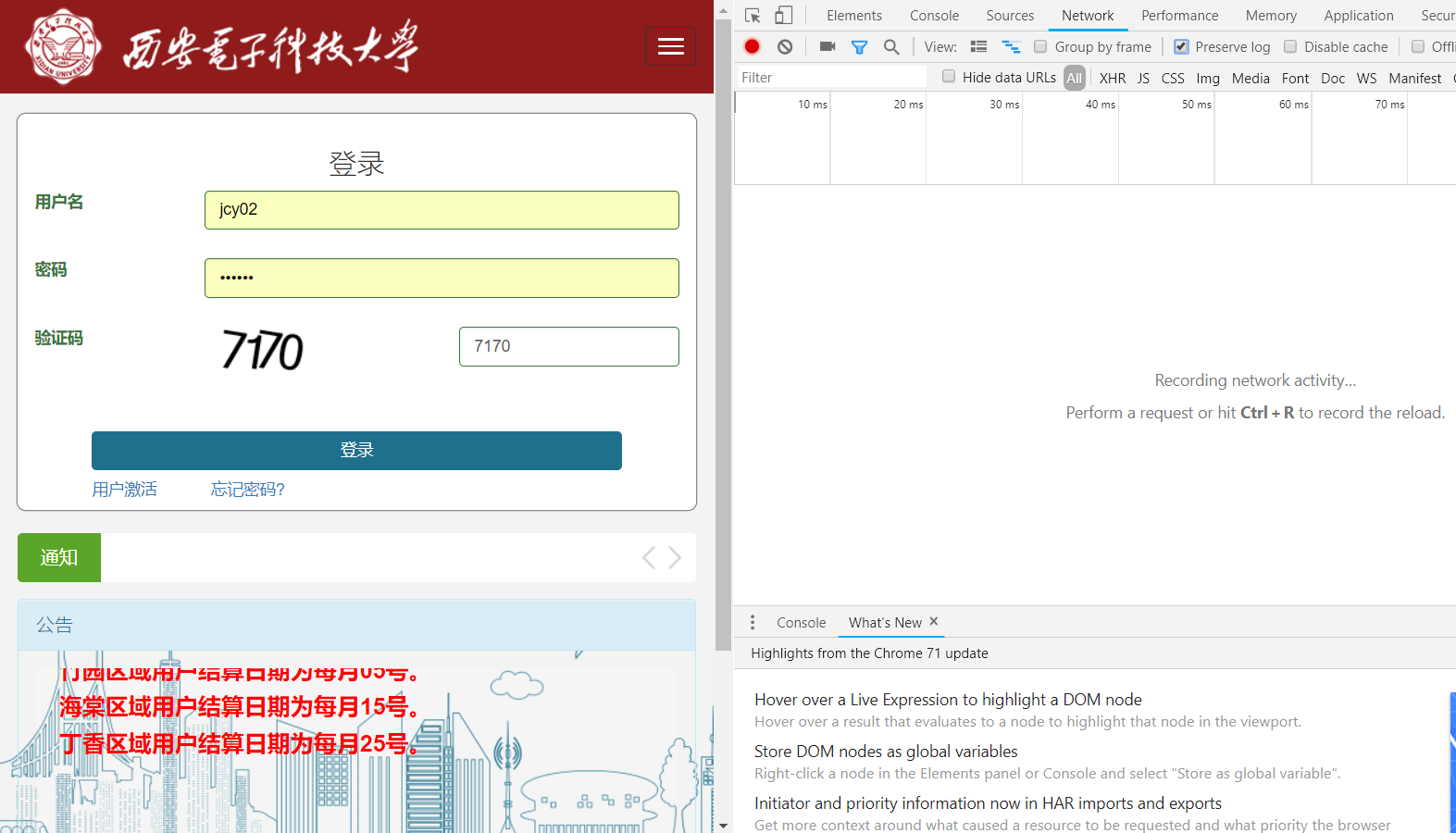
之后正常登陆,就可以看到登陆过程中的request信息,这里在Name一栏,右键勾选Method,再排序,就可以看到登陆时登陆信息(用户名,密码,验证码等)的传输
认证
点击第一条(10.255.44.1)可以查看认证时的具体信息
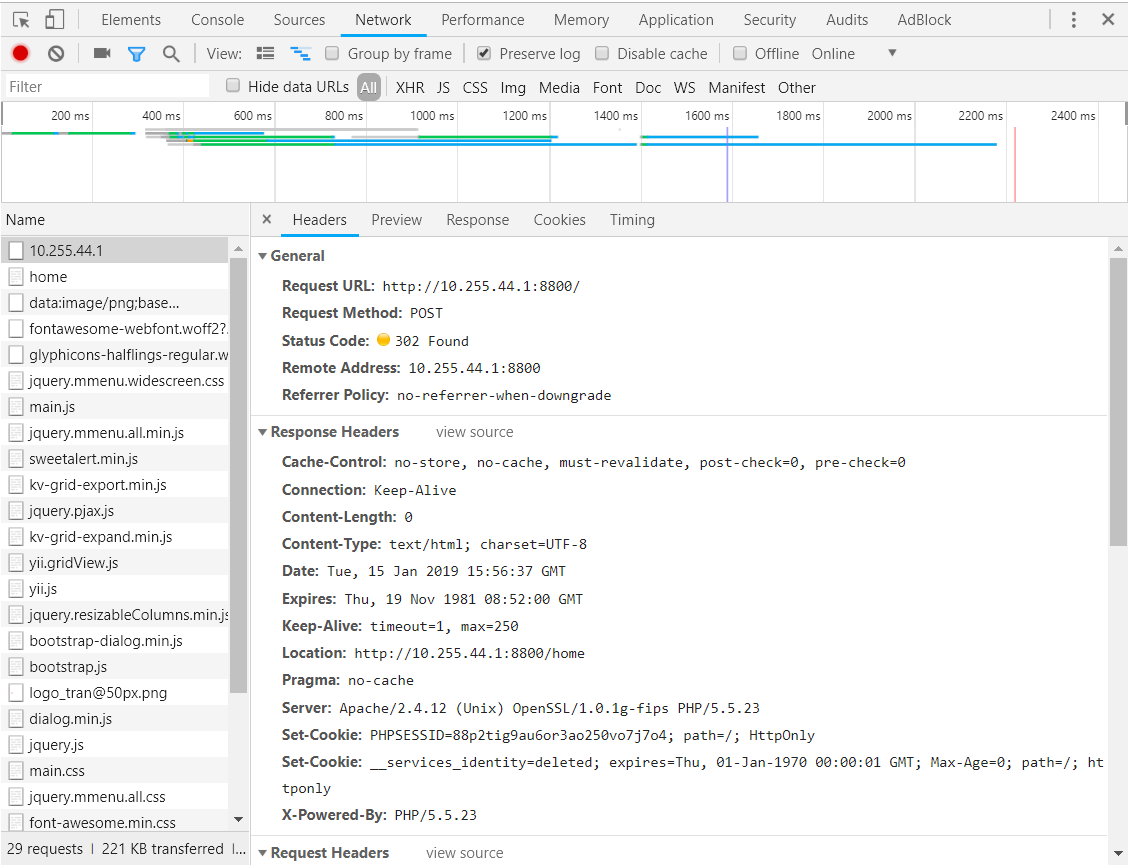
需要关注的内容如下
Status Code: 302 Found
Set-Cookie: PHPSESSID=88p2tig9au6or3ao250vo7j7o4; path=/; HttpOnly
Location: http://10.255.44.1:8800/home
第一条指的是HTTP状态码中的重定向(302 Move temporarily),接收到这条状态码才是认证成功,第二条是post信息被接受后,服务器发来的cookies,用于之后的认证,第三行就是重定向的目标地址,拉倒底部,可以看到POST的信息:Form Data
_csrf: Rk51ek8uenEcBA0UI2ocKxx5EkwobUMzCBctIx5UFAEVPTYpfn0tHQ==
LoginForm[username]: ^_^
LoginForm[password]: ^_^
LoginForm[verifyCode]: 7170
login-button:
第一行是动态变化的字符串,和POST时使用的cookies一同来自于登陆认证网站,具体看cookies一栏
Request Cookies
PHPSESSID k96l966erevuaidlgilu8neok1
_csrf 534478b589686f81bb22e1fa533f2d7ab088fe47
Response Cookies
PHPSESSID 88p2tig9au6or3ao250vo7j7o4
使用第一个Cookies实现了Request POST认证,而Response又返回了一个Cookies,这个Cookies很关键
流量查询
上面的一步仅仅是完成了认证和跳转链接,那么到了流量查询网站又是怎么实现登陆的呢?查看检查工具的第二条(home)的Headers部分:
Request URL: http://10.255.44.1:8800/home
Request Method: GET
Status Code: 200 OK
可以看到这里是向流量查询的URL发送了一个GET请求的Cookies部分:
Request Cookies
PHPSESSID 88p2tig9au6or3ao250vo7j7o4
_csrf 534478b589686f81bb22e1fa533f2d7ab088fe47
这里的Cookies就是上面认证后返回的Cookies,所以这就是“认证——跳转——登陆”的关键了
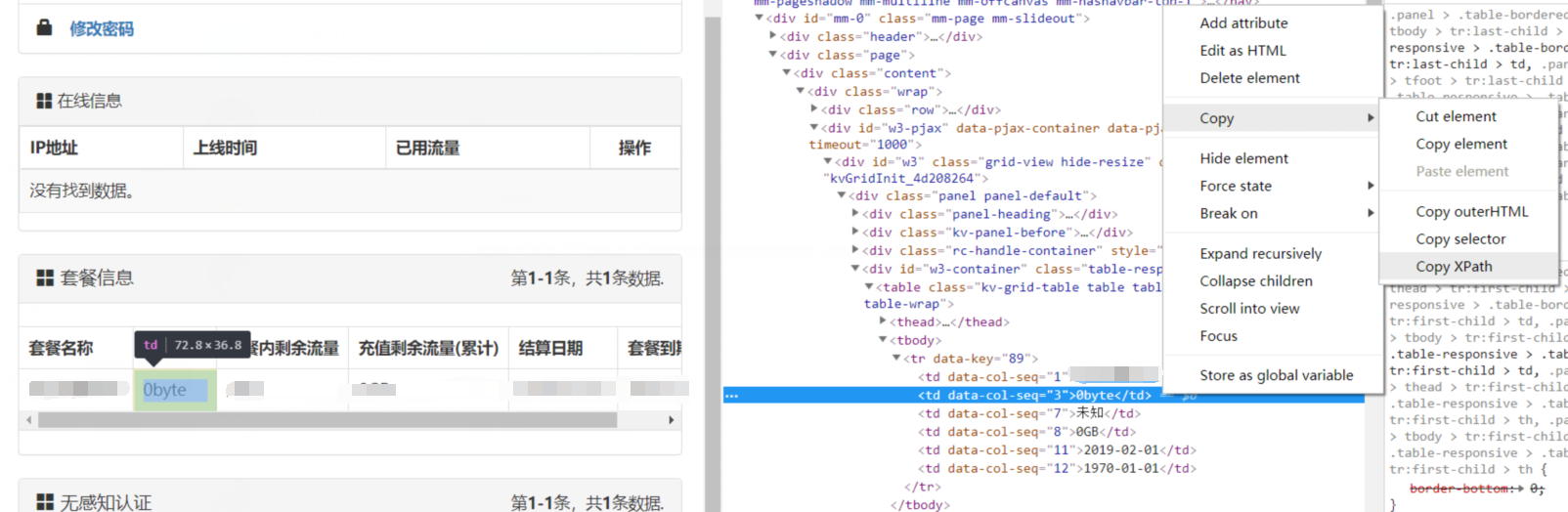
使用XPath获取内容
同样是使用检查工具,相比于正则表达式和BeautifulSoup,对于这种看起来就不好解析的部分,用XPath还是又速度上的优势的,这里爬取的是整个表格,对于XPath也可以找到规律
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
后续
之后简化日常的查询了
如果是Bash的话设置别名相对方便一点
echo "alias NAME='python3 YOUR_SCRIPT_PATH'">>~/.bashrc
source ~/.bashrc
如果是在Windows下的话,别名貌似不太方便
用批处理代替就好,把下面的代码保存为.bat后缀的文件,双击即可运行
python YOUR_SCRIPT_PATH
pause
或者使用scoop提供的别名
scoop alias add NAME 'python YOUR_SCRIPT_PATH' 'YOUR DESCRIPTION'
scoop NAME
如果想要进一步提高识别的准确率的话可以为验证码识别做训练,@lllthhhh 做了这方面的工作,最后的训练数据在lllthhhh/tesseract_data_xdu_pay
添加训练数据的方法:把*traineddata添加到tessdata目录下即可
训练后的一次性识别准确率高于0.71,加上psm以及限制识别范围为数字时准确率有0.35,不加任何的参数的情况准确率只有0.19
运营商流量查询和小组件显示
当前查询运营商流量往往需要频繁打开运营商的APP,占手机空间不说,效率还很低下;使用接口查询的基本原理和前文一致,但是感觉用到的工具先进很多(缺点是接口容易失效),并且因为容易修改有很强的借鉴意义,这里简单写下思路:
- 获取Cookies:
借助iOS下的网络开发和代理工具使用MitM解密HTTPS流量,用boxjs缓存相应APP的cookies
或者 浏览器的网络调试功能(Chrome F12)获取Cookies - 请求:anker1209/Scriptable提供的Scriptable小组件使用获取到的Cookies访问运营商的流量接口获取剩余流量
- 显示:Scriptable小组件可以在iOS设备和Mac常驻显示,并且可以指定时间间隔更新;因为运营商的流量分类复杂,必要的话可以自行修改Scriptable查询和显示的部分代码