网络接入
OpenWrt + 4G 手机
历经多次宽带因为单一运营商垄断,价格高到离谱,之前在学校测过4G是可以跑到100Mbps的下行速率的,买过4G路由器做接入,后来因为SIM卡不够用就出掉了
在5G时代,闲置的4G手机完全可以用来作为网络接入设备,我用刷了OpenWrt的小米R3G有线连接退役的iPhone SE做了一个简单的4G路由器,找个4G信号好的地方固定,测速还行就可以开始用了

因为有部分模块依赖于内核,加上平时编译不太方便,所以采用官方固件,参考官网教程 Smartphone USB tethering
我记录的一些需要装的包
# 换源
sed -i 's_downloads\.openwrt\.org_mirrors.ustc.edu.cn/lede_' /etc/opkg/distfeeds.conf
# 装包
opkg install kmod-usb-net-ipheth kmod-usb-net kmod-usb-ohci kmod-usb-uhci kmod-usb2 libimobiledevice-utils libusbmuxd-utils usbmuxd
opkg install luci-compat
用了一段时间后发现了如下问题,当然也还有其他的手机可以尝试,但是我觉得4G的问题更大:
- 4G的信号不佳,经常达不到预期的100Mbps,这个和户型、运营商都有关
- 4G的网速在不同时间段表现差别很大,高峰期几乎无法上网
ios更新14之后,以上教程提到的方法就失效了,后续就没有在ios上再尝试过了;随着第一代5G手机在2022年陆陆续续退役,5G手机USB共享网络给OpenWrt路由器却没有达到预想中的那么快,考虑到在手机上经过了一次NAT,存在硬件开销以及调度和功耗限制,这还是不适合作为一个长期方案
5G CPE
于是开始关注5G CPE,恰好就遇到了2020年刚上市的华为的5G CPE Pro 2 (型号H122-373,以下简称H122),幸好买的早,后来芯片荒价格一路水涨船高,直到后来智选的5G CPE铺货

当时刚好手上有可以跑千兆5G卡,至少在下载速率上可以超过绝大多数家庭宽带了,缺点也还是有的:
- H122虽然可以放开防火墙,但是只是放开了入站的Input的流量(外部能够ping通CPE),会拒绝Forward的流量,即使下面的终端设备可以获取到IPv6地址,但是也无法从外网直接访问
- 如果长时间高负载,即使内置了一个散热风扇,内部的温度还是比较高的,具体影响是SIM卡会热到变形,所以需要买一个SIM卡接口延长线
- SIM卡不支持热插拔,经常需要换卡的话,要重启CPE,考虑到插槽寿命,SIM卡接口延长线必不可少
- 最想吐槽的一点,CPE的桥模式在某次更新之后就没有了,桥模式可以使得下面的主路由可以自行控制防火墙,如果需要配置IPv6外网访问的话是必要的
- WLAN to 2*LAN 最大只有千兆,让局域网内怎么都跑不满到160MHz WiFi6的速率(一般为实测1.2Gbps以上),充分说明了CPE还是以5G接入为主,5G to WLAN应该是能跑满的
- 支持5G和有线WAN并发,但是实测效果一般,如果有线WAN只有IPv4的话,5G部分可以补充IPv6
写出来有点多,但不可否认的是在很长一段时间里H122就是能买到的最强的5G CPE,在我这稳定运行了三年,因为是价格低位购入,还能直接用天际通物联网卡(23年已经限速到200Mbps,没有了5G SA,只能用4G)
最后需要担心的其实是流量问题,因为5G的流量消耗速度非常快,实时监控流量消耗情况也是必要的,如用iOS小组件;因为华为5G CPE当前已经无法收到短信,流量告警只能自行编写脚本等方式实现
OpenWrt + 4G模块
这里使用的是DJI增强图传模块连接OpenWrt路由器USB接口接入的4G网络
- 个人认为只能算是驱动了基础的QMI拨号上网功能,缺少产品本身完整功能及驱动的说明
- 加了DIY的无人机上的天线,信号还是比手机略差,实测50Mbps-10Mbps传输的速率
- 发热情况在28度的室内属于可以接受,上网基本是稳定的,游戏偶尔会跳ping,4G网络期望不能太高
2022年大疆在Mavic3发布之后发布了与之配套的4G图传模块(DJI Cellular),然而自带的增强图传服务只有一年的套餐,后续如果要继续使用就需要以每年99续费增强图传服务,对于只是想超视距飞行过把瘾的人来说,增强图传服务到期之后模块自然就闲置了(大疆2023年新品不兼容该模块),二手市场上挂出的非常多,感觉出手比较困难(原价699,2023.11二手大把的450),而全新的同规格的Cat4速率的4G USB网卡120可以买到,既然如此,还不如留着当4G网卡发挥余热
驱动的方法
该方法在ImmortalWrt 23.05.1的ARM和MT7621的路由器上测试成功
- 安装QMI拨号需要的包
opkg install qmi-utils usb-modeswitch kmod-mii kmod-nls-base kmod-usb-core kmod-usb-ehci kmod-usb2 kmod-usb-net kmod-usb-wdm kmod-usb-net-qmi-wwan wwan uqmi luci-proto-qmi - USB连接4G模块,执行识别驱动的命令,命令如果没有报错的话,
ls /dev/应该看到cdc-wdm3这个设备了echo "2ca3 4006 0 2c7c 0125" > /sys/bus/usb/drivers/qmi_wwan/new_id - 创建QMI拨号的接口,例如命名为DJI,在调制解调器设备一栏填入
/dev/cdc-wdm3(最关键,下图是借用的其他教程的截图作为参考),其余的信息保持默认; 在防火墙设置,给这个接口分配防火墙区域为wan,保存设置即可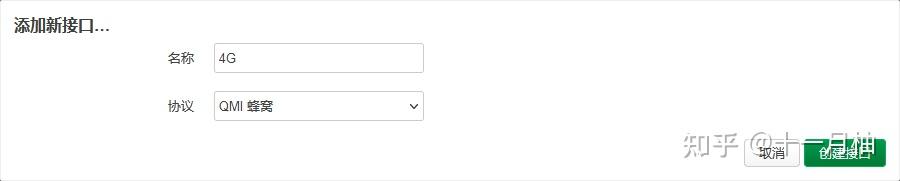
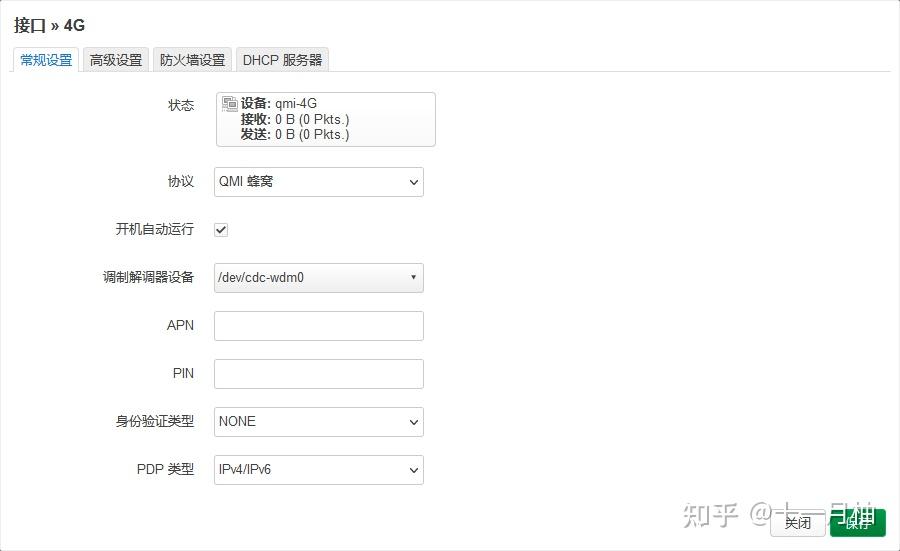
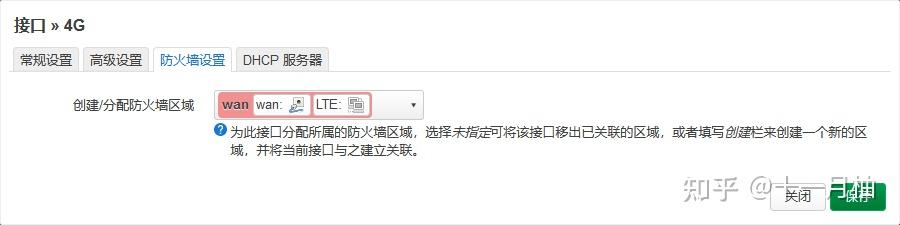
如果此时4G图传模块上的灯是绿色的,即模块正常连上了4G网络,很快能看到刚刚创建的接口已经获取到了IPv6的地址,并且系统自动生成了名为DJI_4的IPv4地址的虚拟接口,此时路由器应该就能通过4G模块访问互联网
第一次成功驱动并设置好QMI拨号的接口后,可以将命令
echo "2ca3 4006 0 2c7c 0125" > /sys/bus/usb/drivers/qmi_wwan/new_id
添加到开机启动脚本中(网页LuCI界面->系统->启动项->本地启动脚本),添加到文本框中exit 0这一行之前即可,后续重启也无需任何的操作,随时插入4G模块后一段时间就能正常上网了
探索的过程
在大疆论坛上有用户尝试了Windows上驱动并成功让PC能接入4G网络,后续大疆又发布了模块的Windows驱动,其中主要提供了以下的信息:
- PC直接识别的型号是EG25G-QDC507,其中EG25是移远(Quectel)的产品:一款Cat4速率的4G模组
- 4G模块正常驱动后显示的生产商为Baiwang,查不到驱动和规格相关的信息
搜索OpenWrt上驱动模块的资料,发现在OpenWrt上移植EG25驱动的经验是空白的,主要都是移植EC2X的,其中《挂载移远EC20、EC21、EC25、AG35等4G模块》参考了官方的Linux驱动文档,EG25在文档发中和EC25的PID和VID是相同的(2C7C, 0125),但是与4G图传模块的(2CA3, 4006)不同,即使移植了EG25的驱动也未必能识别到4G图传模块
直到看到论坛里有人发了4G图传模块用于Linux系统上网尝试,用到了将USB设备的PID和VID写入/sys/bus/usb/drivers/…/new_id处理驱动识别的方法,另外又查到了23年11月的OpenWrt 下实现移远 4G 模块上网 中提到在OpenWrt 22.03在无需改内核代码就能驱动EC20
在运行echo "2ca3 4006 0 2c7c 0125" > /sys/bus/usb/drivers/qmi_wwan/new_id后,可以用cat /sys/kernel/debug/usb/devices查看到4G模块被qmi_wwan驱动(设备对应的信息出现Driver=qmi_wwan字样)
在/dev目录下可以看到/dev/cdc-wdm[0-3]一共4个设备,最开始尝试了/dev/cdc-wdm0发现无法拨号就差点放弃,最后尝试了下/dev/cdc-wdm3发现拨号可以获取到IP了
查看信号及IPv6情况
uqmi命令可以与模块通信并输出一些状态的信息,其中个人比较关注的主要是信号
root@XDR6088:~# uqmi -d /dev/cdc-wdm3 --get-signal-info
{
"type": "lte",
"rssi": -55,
"rsrq": -6,
"rsrp": -79,
"snr": 14.800000
}
4G模块的速率标准为Cat4(下行速率最高150Mbps,上行最高为50Mbps),实测在以上信号强度的电信4G上下行均为50Mbps左右,日常用这速率也算能接受吧,联想到我测试过最快的4G是2018年在iPhoneSE(4G Cat6最高下行速率300Mbps)上跑出了100Mbps的下行
关于IPv6,首先路由器时可以获取到公网IPv6地址的(以及64位前缀的PD),并且在LAN默认的IPv6设置下,可以向下分配地址,另外就是传入连接的连接性,实测发现有运营商的差异:移动的IPv6地址无法从外网访问路由器,联通和电信的IPv6地址则可以
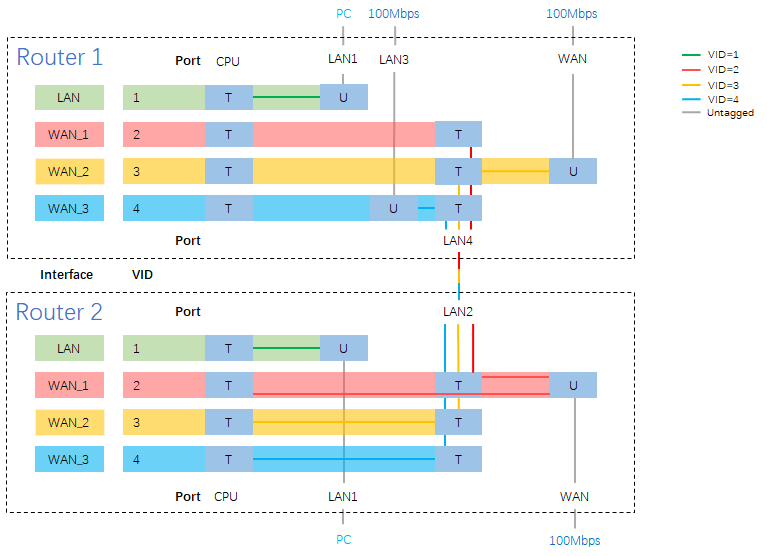
CPE/4G模块下的二级路由
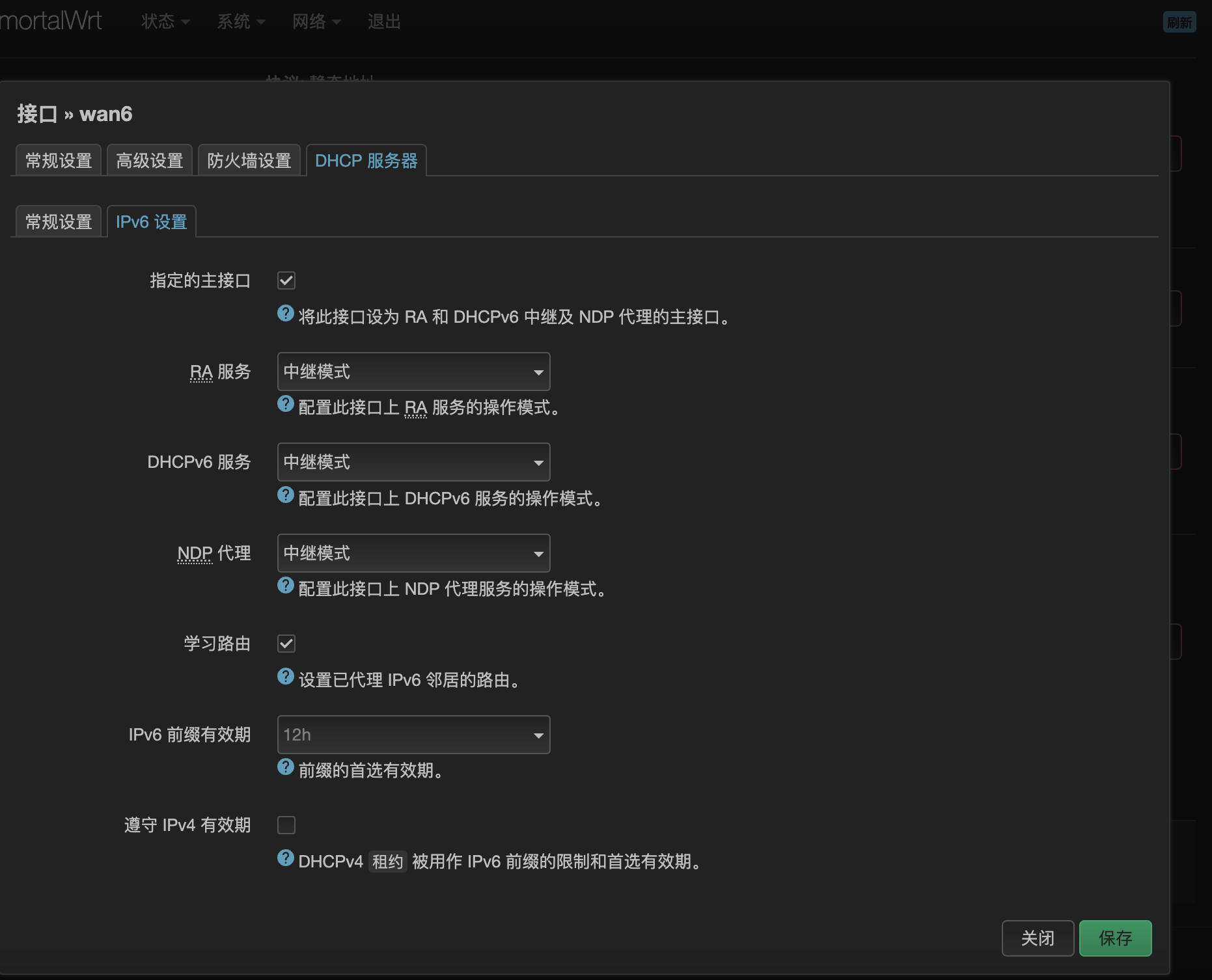
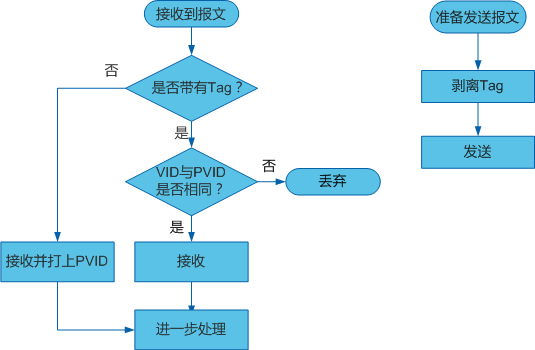
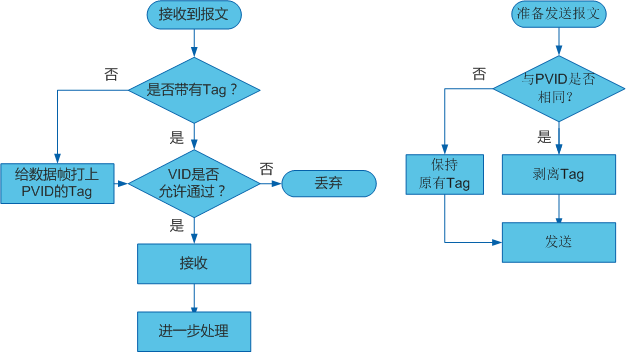
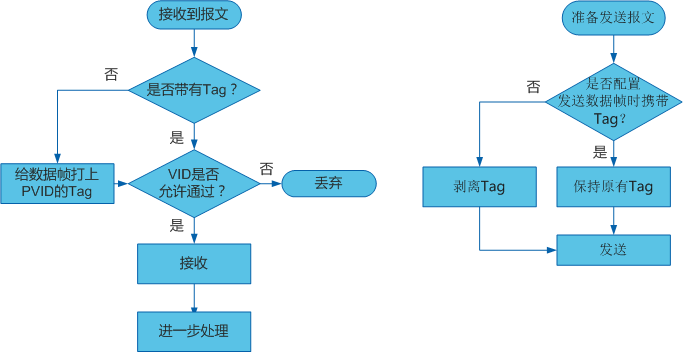
由于CPE和4G模块获取的IPv6地址是不含短于64位的前缀的,所以在使用二级路由的情况下,二级路由下的设备无法获取公网IPv6地址,这个时候需要配置“IPv6中继+NDP代理”,OpenWrt 23.05的LuCI界面的设置过程如下:
- 比如wan6接口已经获取到IPv6地址,下面都是在默认的设置上修改的,第一张图的设置不需要改
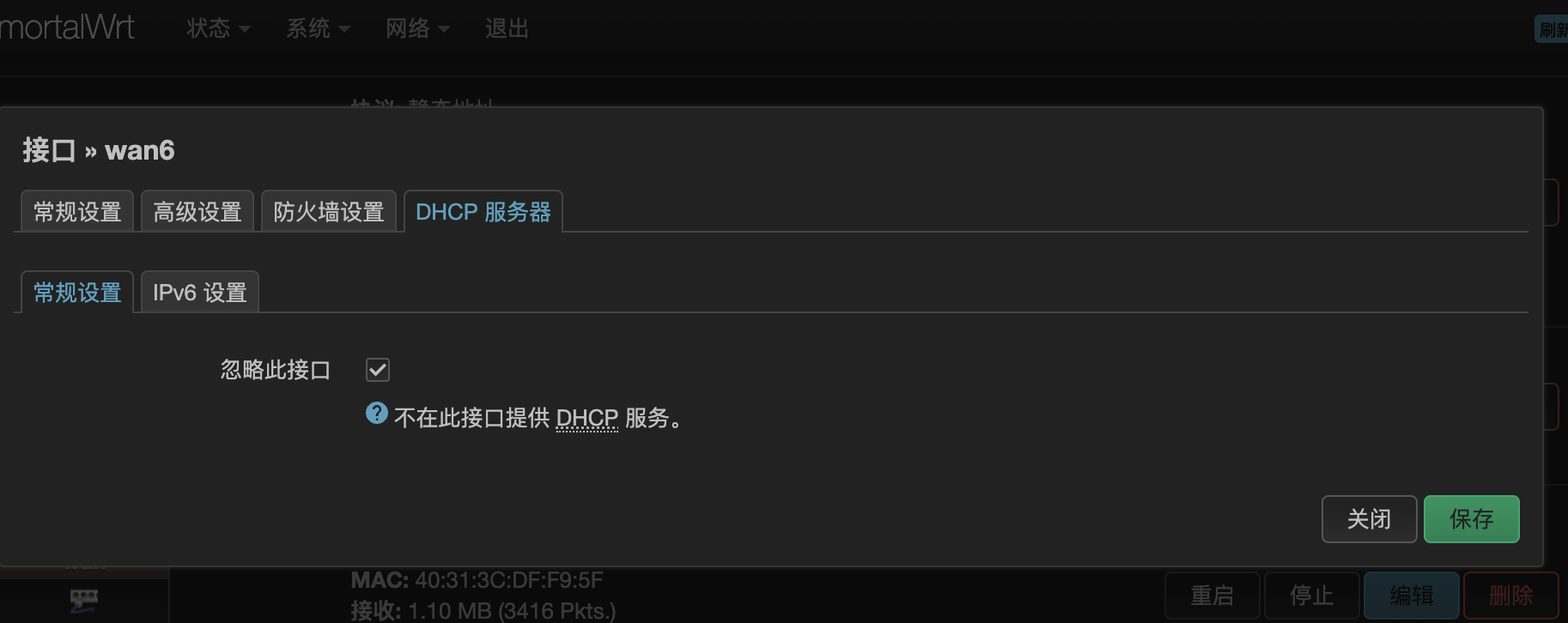
- wan6接口的设置勾选指定的主接口,接下来三个地址分配的选项选中继,学习路由要勾选
- lan接口的设置,三个地址分配的选项选中继,学习路由要勾选
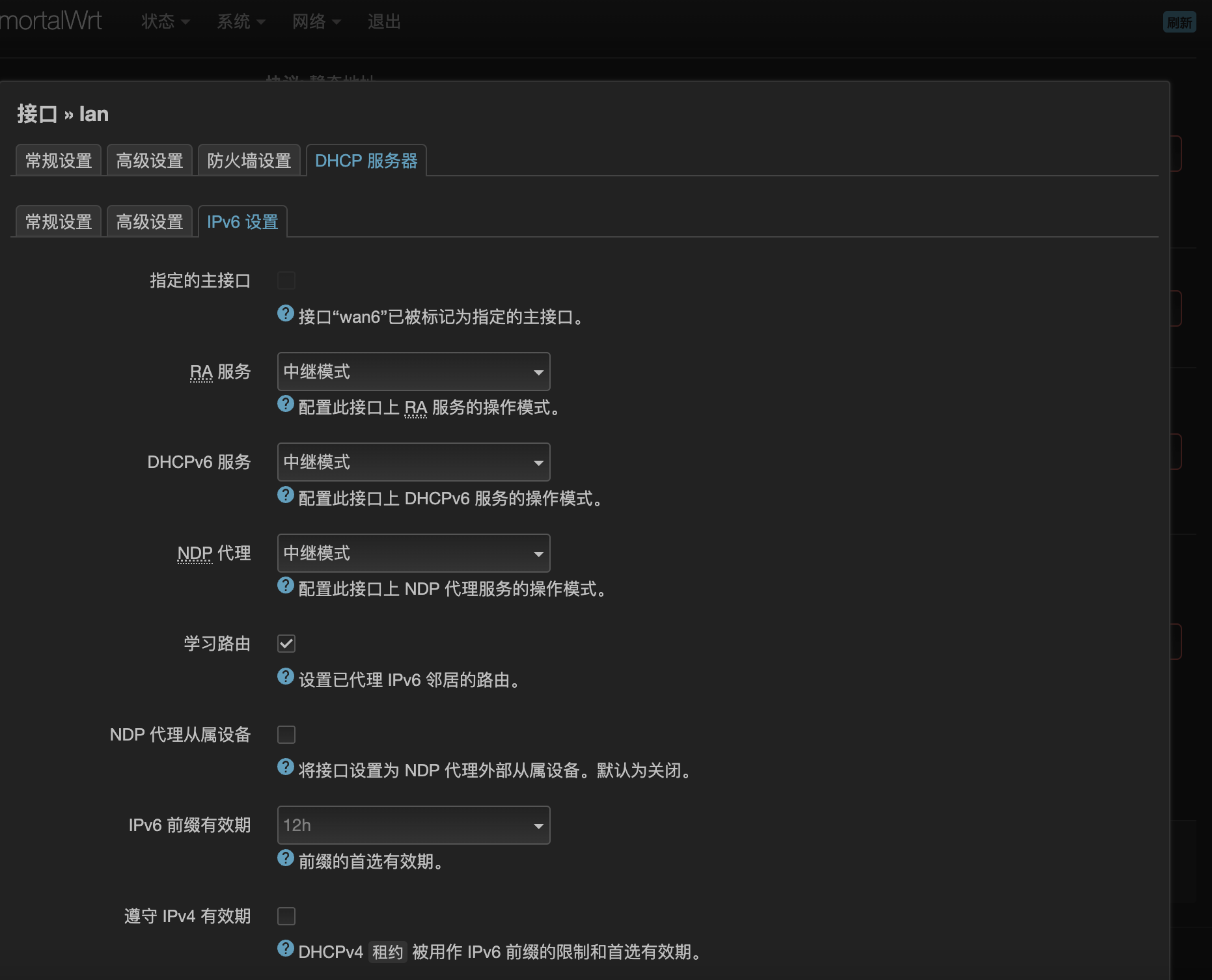
- 删除ULA前缀(这里是经验之谈)
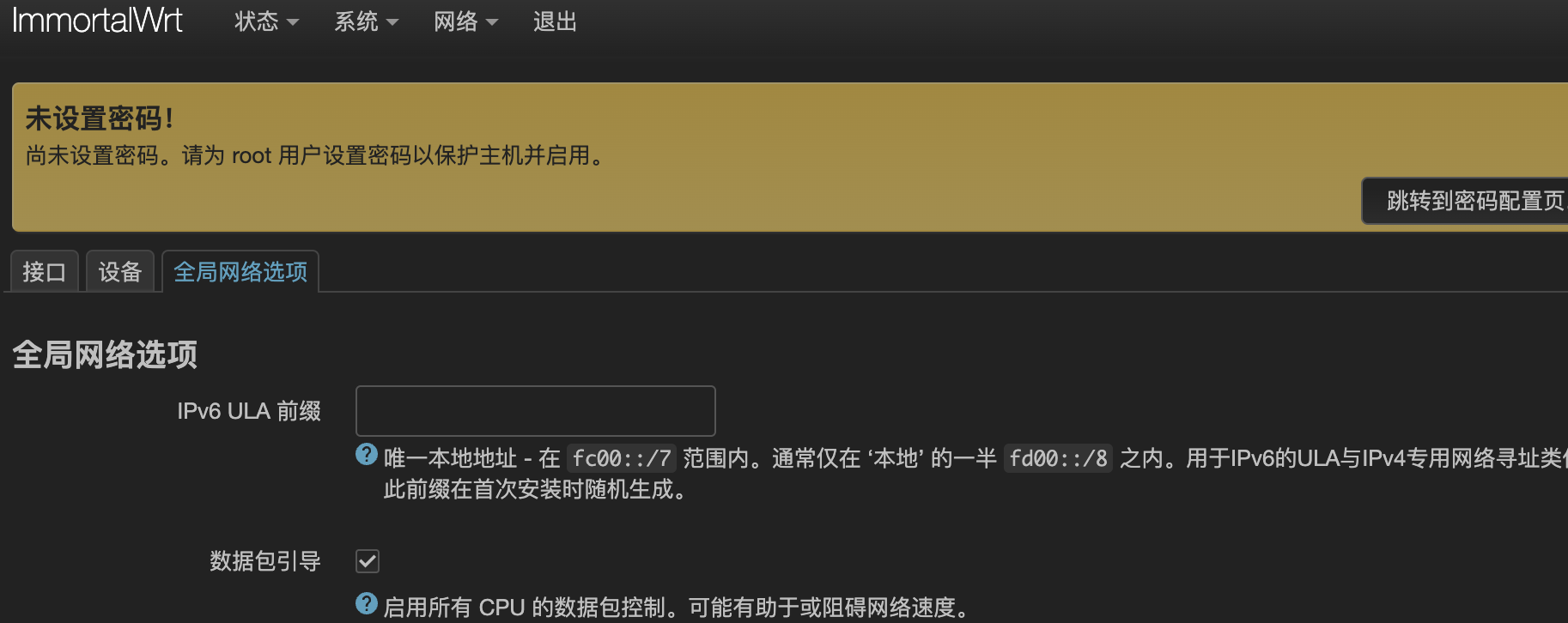 正常情况下,连接在路由器下面的设备就能获取到公网IPv6地址了,但是可能还打不开IPv6网站:http://test6.ustc.edu.cn,这个时候可能需要ping一下wan6接口的IPv6地址,让地址被NDP代理学习(可以用
正常情况下,连接在路由器下面的设备就能获取到公网IPv6地址了,但是可能还打不开IPv6网站:http://test6.ustc.edu.cn,这个时候可能需要ping一下wan6接口的IPv6地址,让地址被NDP代理学习(可以用ip -6 neigh和LuCI上的系统->路由表->IPv6邻居看IPv6地址对应的接口来观察NDP代理的效果)
我的网络结构是CPE做一级路由,OpenWrt做二级路由,因为华为5G CPE本身防火墙的原因,二级路由下面的设备可以获取到IPv6地址,但是无法从外网访问
但是如果CPE或者4G模块支持桥模式,那么OpenWrt路由器大概率是不受CPE或者4G模块的防火墙影响的,放开OpenWrt的防火墙之后,只剩下运营商屏蔽了传入连接的可能性
局域网
局域网肯定还是要用一台OpenWrt路由器作为主路由,如果一台主路由能解决问题是最好,列出来的要求有点多:
- 网口足够多,早期的路由器一般是5个千兆口(1 x WAN + 4 x LAN),勉强够用(PC + NAS + xx),如果带USB口的话,还能额外扩展网口
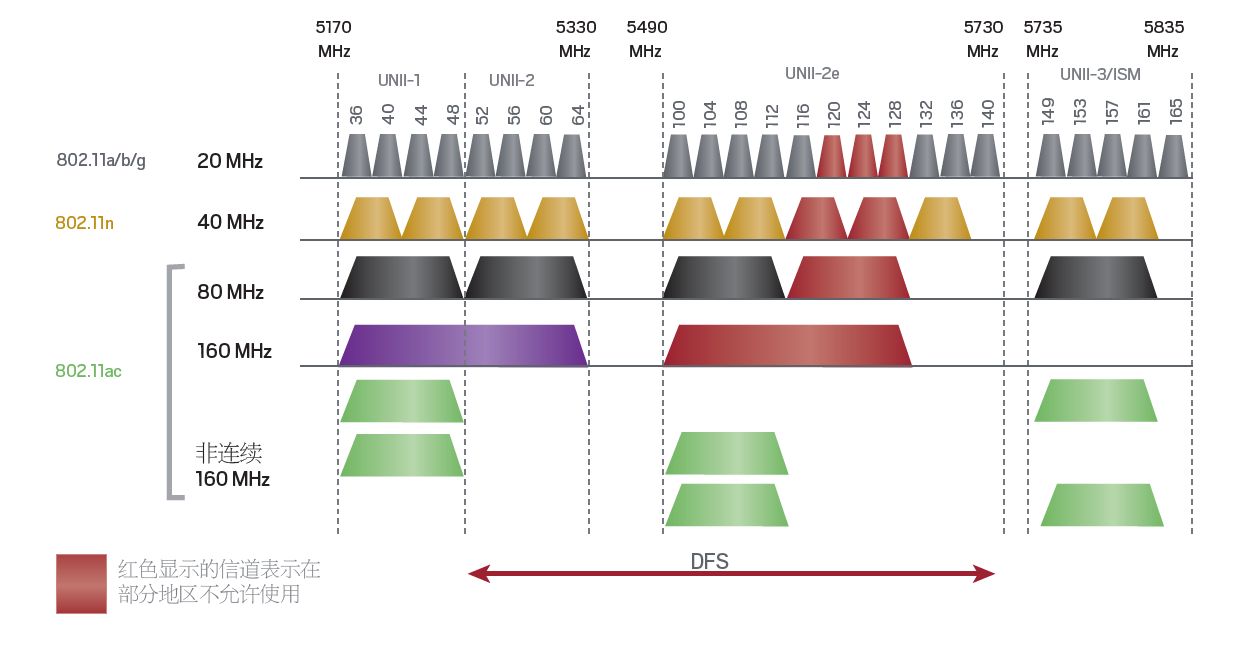
- 最好有2.5G以上的网口,因为160MHz WiFi6已经可以跑到1.6Gbps以上了,当前NAS的机械硬盘读写大多能超过200MB/s,2.5G网口的设备会越来越多
- WiFi 4T4R(4x4 MIMO)信号更好,有MU-MIMO的情况下,当前主流2x2 MIMO的多台设备可以同时高速传输
- 有良好的OpenWrt支持,这里特指最好是有OpenWrt官方的支持,开源的固件能确保基本的功能正常(21年之前WiFi6的开源驱动很少有能用的)
在从2020年到2023年这一段时间里,涌现了一大批可以刷OpenWrt的WiFi6路由器:Qnap-301w、红米AX6,AX6000、中兴NX30 Pro,以及可能有QSDK固件的小米万兆路由,对比以上的要求有明显的短板,直到某一天看到B站上有人给TP-LINK XDR6088刷机的教程:TP-link路由器XDR6088、6086、4288刷openWRT,我终于发现了一台有潜力的机器:
- 带2个2.5G网口 + 4个1G网口 + 一个USB3.0接口
- 支持4T4R 160MHz的5G频段WiFi6
- 4*A53@2.0GHz的CPU,128MB的闪存在2023年够路由器装常用插件了,看拆机散热算是比较好的
XDR6088刷OpenWrt
可以查到的获取终端操作权限刷入U-boot(bootloader)的方法源于:TP-LINK XDR6086/XDR6088 反弹 SHELL 并开启 SSH
综合亲手实践以及上面的视频教程,有几点需要特别注意
- 实测在1.0.24版本到1.0.23都可以通过反弹shell注入命令,切记每次发完post请求之后,禁用用户触发反弹shell完成后,删除用户,这样下一个Post请求才能发送成功
- 发Post请求的客户端软件有特别的要求,我试过OpenWrt,CentOS,群晖,Postman的curl命令/Post请求发送均无法创建VPN用户,最后还是重装了一个Ubuntu的WSL才成功:返回
{"error_code":0} - 在Windows下使用nc导出路由器备份的mtdblock的时候,Windows上一定要用CMD运行nc并重定向(
nc -l -p 9995 > backup.img),不能用Powershell(备份传输完成后,校验的话就会发现用Powershell运行同样的命令会得到不一样的文件),因为这一条操作失误导致我刷OpenWrt后刷回原厂系统的过程中导致变砖 - 视频教程中的UBoot刷完后,通过这个UBoot是无法直接刷入官方的OpenWrt固件的,原因是分区结构不一样,本文后面有记录刷到官方的方法
一些简单的测试
我只刷了视频教程的固件,基本上是截至到当时最新的R23.5.1,2.5G网口和WiFi稳定的运行两周,这里先放下收集到的参数的对比,至少CPU的参数在当前WiFi6末期可刷机硬路由中基本上是第一档的
| 路由器 | CPU | RAM | ROM |
|---|---|---|---|
| Newifi Y1 | MT7620 1C@580MHz | 128MB | 16MB |
| K2P | MT7621AT 2C4T@880MHz | 128MB | 16MB |
| XDR6088 | MT7986A 12nm 4*A53@2.0GHz | 512MB DDR3 | 128MB |
| NX30 Pro | MT7981B 12nm 2*A53@1.3GHz | 256MB DDR3 | 128MB |
| Qnap-301w | IPQ8072A 12nm 4*A53@2.2GHz | 1GB DDR3-1600 | 4GB |
| K3 | BCM4709 40nm 2*A9@1.4GHz | 512MB DDR3-1600 | 128MB |
| N1 | S905D 28nm 4*A53@1.5Ghz | 2GB | 8GB |
- 近距离WiFi6设备测速,用支持160MHz的小米13可以跑出1.6~1.8Gbps的速率,支持80MHz的iPad Pro能跑到900Mbps 同一房间,无遮挡用AX200也能跑到1.6Gbps左右
- 中距离WiFi6设备测速,一堵墙的情况下,XDR6088能跑1Gbps,对比4T4R 80MHz的K3能跑400Mbps左右
- 夏天室内29度左右,长时间开机运行,CPU温度不超过60度,机身有热感
救砖
上文提到Powershell下使用nc命令重定向的备份大小异常的问题,相关的原因查明在:Powershell与bash的重定向的差异,在搞清楚其中的原理后,我理解无法通过简单的操作使得备份还原,于是在论坛找到了别人的备份的mtdblock9尝试救砖,参考
- 6088 mtd9分区的备份
- OpenWrt官方论坛讨论XDR6086的帖子有提到用CH341及WSON8探针救砖
- 轻舟XDR6088拆机:闪存芯片型号是F50L1G41LB,容量128MB
- 红米AX6000救砖:红米AX6000使用的闪存是ESMT F50L1G41LB,容量128MB,3.3V的SPI NAND
因为我之前给T440s修改BIOS买了CH341A编程器和8pin的夹子,所以就鼓起勇气拆机,经过艰难的掰卡口后,很快就遇到了问题:
-
红米AX6000救砖中提到建议改CH341的输出电压为3.3v,这个要飞线,我没有工具:
-
我查了下ThinkPad BIOS芯片W25Q32V的datasheet,发现支持的也是2.7~3.6V,之前成功刷上了BIOS,通过不严谨的推测,不修改CH341的输出电压也能刷2.7~3.6V的F50L1G41LB
-
店家给的CH341的编程器刷写软件不支持F50L1G41LB,红米AX6000救砖中提到“NeoProgrammer不知道如何写入单独分区,我选择了SNANDer”:
- SNANDer大概是缺少说明,我这里用的不太顺利,最后还是选了NeoProgrammer,因为后者能成功识别到芯片并读写
-
最棘手的问题在于,F50L1G41LB相比W25Q32V,夹子的触点难以夹到芯片的针脚,无法稳定连接就无法写入,红米AX6000救砖中用的漆包线飞线
- 我买了电烙铁,尝试飞线,但是实在是不会用锡焊,意识到用力过猛可能会损坏芯片,遂另寻他路
- 最后在网上看到了生产用的治具,有一个工作台能将探针垂直于主板放置,探针尖直接接触芯片针脚,然而治具带工作台价格上百,WSON8探针(匹配芯片尺寸8*6mm)比CH341编程器加上夹子还贵一些,自己拼凑了一个固定探针的框,如图:

刷入官方OpenWrt
在OpenWrt官方23.05正式版支持XDR-6088的固件后,参考了TL-XDR6088/6086 刷入官方 Openwrt/Immortalwrt,原文已经记录的相当的详细,此处仅摘录用到的步骤(因为独立博客的域名过期之后就很可能找不到原文了)
本文写作时,最新的是23.05.0-rc3版。将来请用更新的稳定版本,目前Immortalwrt官方固件已经支持:
- 双 2.5Gb 网口的正常驱动(但LED灯还不亮)
- WiFi6 160Mhz
- 硬件流量分载
- WED (Wireless Ethernet Dispatch) 无线加速
- 硬件 NAT 加速
- Fullcone NAT
4.2 如果路由器已经刷了其它版本的 Openwrt
在 Openwrt 中运行
cat /proc/mtd,得到mtd设备的真实命名,再用命令来写入(将下面的BL2或FIP改成你在上面看到的名字,注意大小写)md5sum /tmp/preloader.bin mtd erase BL2 mtd write /tmp/preloader.bin BL2 mtd verify /tmp/preloader.bin BL2 md5sum /tmp/bl31-uboot.fip mtd erase FIP mtd write /tmp/bl31-uboot.fip FIP mtd verify /tmp/bl31-uboot.fip FIP注意查看上传的两个文件 md5 并和本地文件对比,查看两次 mtd verify 最后是否输出输出 Success,没问题才可进行下一步。
5. 通过 tftp 载入 recovery 镜像
这时候你可以拔掉路由器的电源,然后插上。直接拔电源可能是最安全的,因为如果你用 reboot 命令,可能会有一些后台程序运行(包括可能你之前在慌乱中没有杀掉的误操作了的 dd)导致路由器变砖。别问我是怎么知道的。
此时 tftp 服务器上应该已经有提示了,路由器在请求的文件名为 openwrt-mediatek-filogic-tplink_tl-xdr6088-initramfs-recovery.itb 。你只需要把结尾为 recovery.itb 的文件,改名为这个就行了。
如果没动静,你可以拔下电源,然后顶住 reset 孔不放,同时插入电源,应该会看到 LAN 口的灯齐闪一下。大约10秒钟,应该就会进入 recovery 模式。确保网线插在 1Gb LAN 口上,网口的灯应该会亮的。
NAS加装万兆网卡
前面提到了WiFi6 160MHz普及之后,局域网传输的瓶颈主要在千兆的有线网口上,考虑到外置USB网卡(USB 3.0外置网卡最大速率为5Gbps)可能因为发热等因素不稳定,首选的话还是PCIe的网卡,而且由于数据中心万兆网卡下架,市面上有较多的低成本的选择,在网络讨论的最多的是浪潮X540-T2拆机卡,价格大概70左右,特别之处在于PCIE插槽是X8+X1,如果要用的话x1要绝缘屏蔽,我实际使用发现卡兼容性不太好:
- 铝制的小面积散热片,只要插上PCIe插槽就非常烫
- 插在群晖的NAS上发现无法识别
- 插在z370主板上,概率性无法识别,或者iperf3测速不稳定
- 最后是X540本身,由于年代久远,不支持协商以太网的2.5G速率
最后捡到一张180的带华为物料编码的x540,有几乎覆盖整个卡面的黑色散热片,插上群晖DS1621可以直接用,对于装了驱动的Z370-I也是

简单测了下,这张x540的空载功耗大约是8w,看卡背面的便签写着silicom PE210G2I40E,查到了silicom官网关于电口万兆网卡的功耗,找到了“电口功耗高”的依据:
PE开头的NIC(网卡)均为silicom官网上的网卡的功耗数据(均为所有端口Link/Idel 的功耗的整卡功耗),可以看到x540的功耗一骑绝尘,考虑到网卡的成本以及长期电费,最后我找了一张AQC107的网卡LREC6880BT,也把数据列到了下面:
| NIC | Controller | 无Link | GE | XGE | |
|---|---|---|---|---|---|
| PE310G2I50-T | X550-AT2 | 4.62W | 5.4W | 8.16W | x4 PCIe 3.0 |
| PE210G2I40-T | X540 | 7.23W | 7.92W | 14.28W | x8 PCIe 2.1 |
| PE310G2I71-T | X710-AT2 | 3.6W | 5.52w | 8.28W | x8 PCIe 3.0 |
| PE310G2I71 | X710BM2 | 3~4W | 4.6~4.8W | x8 PCIe 3.0 | |
| PE210G2SPI9A | 82599ES | 4~6W | 6W | x8 PCIe 2.0 | |
| LREC6880BT | AQC 107 | 网卡4.7W | x4 PCIe v2.1 |
数据中心下架的卡基本上都有些年头了,关于网卡的控制器、发布时间、制程、TDP,2022年末的二手价如下:
| NIC | Controller | TDP | Release | Process | Price |
|---|---|---|---|---|---|
| 华为SP230电 | X540-AT2 | 12.5W | 12Q1 | 40nm | 250左右 |
| Intel X550 | X550-AT2 | 11W | 15Q4 | 28nm | 1200左右 |
| Intel X710-T4 | XL710-BM1 | 7W | 15Q4 | 28nm | 2450 |
| X520-DA1 | 82599ES | 09Q2 | 65nm | ||
| LREC6880BT | AQC107 | 6W | 17Q4 | 28nm |
在网上看到说Intel的X540和X550在群晖的DSM系统中是免驱的(其实是DSM的Linux带了驱动),因为X550太贵,所以把目光投向了价格和功耗都合适的AQC107,因为群晖E10G18-T1 10G等群晖官方的万兆电口卡也是用的AQC107,我天真的以为第三方AQC107也是免驱的
群晖DSM7.1编译AQC107网卡驱动
网上我能找到两个中文的经验:
- 历尽磨难,群晖Dsm7.0编译E10M20-t1(aqc107)网卡驱动,终获成功!,论坛里的过程记录贴比较冗长,而且方法相对下面的原生方法要逊色一些,图方便的话,帖子应该是提供了编译好的驱动
- 搭建群晖 Synology NAS 开发环境,自编译网卡等驱动 我主要参考的这篇文章,我的编译过程与文章有几点不同
- 编译的依赖不同,毕竟编译的驱动的文件是不一样的嘛
- 我手动链接了更多的文件/文件目录
详细的要二次编译成功再补充,大概是下次DSM系统版本/内核版本更新
Z370-ITX使用64GB内存
因为不涉及到后面的修改BIOS文件就能上64GB内存,这里直接上结论:
- 实测在华硕Z370-I的1410版本的BIOS,可以识别到64GB内存并开机正常使用,使用的内存是2条金士顿Fury DDR4 32GB 3200MHz
在我的平台上,用最新的3005的BIOS反而会导致莫名其妙的自动重启
- 关于CMD运行命令“wmic memphysical get maxcapacity会显示最大支持的内存”,实测是不准确的
- 华硕这块ITX的主板的BIOS文件的 最大内存限制的二进制位 与 已有经验反馈的ATX主板BIOS文件的不同,所以最后还是实践出真理
因为在互联网上找不到Z370-I成功实践的经验,所以这里留个记录:
Asus Z370-I是一块ITX主板,只有两个内存插槽,装机的时候切好碰上DDR4内存天价,所以很长一段时间里只有双通道16GB 3000MHz,这块主板在官网上参数写着最大支持32GB内存,也就是2X16GB,然而随着内存降价,发现23年单条32GB的内存已经很便宜了,想着直接上到双通道64GB,以后这台机器退役也能当服务器用
32G单条内存的颗粒检索
因为是捡垃圾买到的“Fury DDR4 32GB 3200MHz”,想要知道超频情况,无法在thaiphoon burner中识别出具体的镁光颗粒,所以只能通过拆内存条散热马甲查看颗粒的FBGA Code(或者叫Market Code:颗粒第二行的编码,例如比较流行的镁光超频内存条C9BJZ),然后在官网Micron FBGA and component marking decoder查询,然而如下的丝印代码在官网是查不到的:
3CE22
Z9XJP
最后是在电子元器件网站上检索到了颗粒的型号(Part Number):MT40A4G8VNE-062H ES:B;根据镁光的PART NUMBER命名规则表,可以获取到如下信息:
- 频率:062对应3200MHz
- 内存条单面八颗粒,叠die颗粒(4G8 4Gb*8 为2Gb的2G8的叠die版本)MT40A4G8 这个是叠die的颗粒
- 然后是ES是工程样片,对应Market Code第一位为Z
然后因为网上搜索不到相同的颗粒,所以超频抄作业可以不用想了,只能搜索到酷兽银甲单条32g 颗粒分析和超频也是叠die颗粒超频:“3200频率下1.45V时序可压c14-18-18-34,这里简单调了下一二时序,能效可以达到4.8w左右”,我看到了这个之后就按照文中提到的时序调整,实测不需要以上那样的参数,1.35v c14-18-18-32即可,其他的时序参考网上的超频教程进一步收紧,TM5跑不过就放开一点(tRFC为500),最后时延能控制在52ns左右(收紧的话可以49ns但是TM5报错)
修改BIOS提升内存支持上限
我搜到了CHH的帖子:首发!Z170/Z370 突破内存64g可用的上限限制,精华在评论里,总结如下:
如何使 H310C/B365/Z370 的 BIOS 支持最大 128G 内存:
1.UEFITool提取SiInitPreMem模块,GUID为A8499E65-A6F6-48B0-96DB-45C266030D83 2.UEFITool搜索“C786….000000….00”,其中“..”为任意HEX值 3.第一处“….”不用理会,第二处“….”如果是“8000”那么就是最大64G,如果是“0001”就是最大128G 4.将“8000”修改为“0001”可破除64G限制 5.100/200系BIOS内也有此内容,理论上6-9代的IMC支持的内存没差,6700+Z170也能128G内存(已测试可行) 6.我这边看,MSI的Z370,18年底的BIOS还是8000,19年4月的BIOS就是0001了,ASUS的BIOS一水的都还是8000 7.ME 需要禁用(修改Flash Descriptor的HAP Bit,但要注意部分主板有校验不允许这么改,改后无法开机) 8.部分BIOS需设置 Chipset->System Agent (SA) Configuration->Above 4GB MMIO BIOS assignment->Disabled 不同 BIOS 位置不同,且可能被隐藏,无法直接修改
注:参考后面的引用,第七步为:将 0x102h的位置 +1
Z370-I的BIOS的修改追踪
限制内存大小的字段,在我的主板上看到的是
# 3005 BIOS (2000 我觉得是单条16G,或者单DIMM 32G)
#Hex pattern "C786....000000....00" found as "C7866F25000000200000" in TE image section at header-offset 388FCh
C7 86 6F 25 00 00 00 20 00 00 EB 20
6A 00 56 E8 B4 E0 FE FF 59 59 0F B6
# 纯血的370ROG已经提供了128G的bios( 2021-2-15 )
# 3004 BIOS 2021-04-16 发生了变化,没有了老版的第二行
C7 86 6F 25 00 00 00 20 00 00 EB 20
# 1802 BIOS
C7 86 6F 25 00 00 00 20 00 00 EB 0A
C7 86 6F 25 00 00 00 80 00 00
# 1410 BIOS
Hex pattern "C786....000000800000" found as "C7866F25000000800000" in TE image section at header-offset 384ACh
C7 86 6F 25 00 00 00 20 00 00 EB 0A
C7 86 6F 25 00 00 00 80 00 00 8B C3
“18年底的BIOS还是8000,19年4月的BIOS就是0001了”的这一行去掉发生3004(更新日志:主要是添加了Win11的支持,没有提内存上线变化),我找了M10H ROG MAXIMUS X HERO BIOS变更日志中有内存上限修改(Support Max DRAM Total Capacity up to 128 GB.)的新老BIOS看了下,也是去掉了8000这一行
恩杰H1自带140水冷老化
这个问题能搜索到公开的文字信息不多,主要的问题是用了一段时间之后散热能力迅速衰减,比如新购入可以压制170w发热的CPU(已经开盖换液态金属),然而老化之后散热能力在CPU功耗80w左右温度就冲击100度,网上能搜索到的维修和拆解分析的经验:
- Youtube上维修的视频 NZXT H1 PUMP FAILURE (AND FIX)
- CHH论坛的帖子(可能需要登录,晚些可能会被归档):水冷头杂质阻塞
- 恩杰H1水冷的水泵损坏的案例也有恩杰H1开机水冷90度怎么办
我拆开水冷头之后,果然如上面引用所述是杂志堵塞了水冷头的微水道,用蒸馏水冲洗了几轮水路,最后换了蒸馏水之后散热能力重回170w,另外水冷的大风扇,对内存散热也要更友好(换用了一段时间的AXP100,内吹的时候内存太烫了)
]]>


 拖动有些卡顿,打开的时候窗口大小有些异常,不过,不影响代码体验~(笔记本上可能对GPU负担太大从而影响续航)
拖动有些卡顿,打开的时候窗口大小有些异常,不过,不影响代码体验~(笔记本上可能对GPU负担太大从而影响续航)