查询宿舍电费余额的爬虫脚本,提供了两种方案:传统的request库;使用selenium,另外写了shell脚本和Dockerfile方便部署记录,在不需要识别验证码之后,完全可以把记录电费的任务交给OpenWrt来做了
电费查询脚本
代码见Github,xidian_script仓库
这是针对西安电子科技大学能源管理系统查询网站写的一个查询脚本,主要解决了以下问题:
- 支持Win/Linux命令行运行,无需读写额外的文件
- 自动识别和输入验证码
Update:时隔半年,通过请教学弟,找到了不需要验证码的接口,还找到了用request登陆的正确方法,本文的大部分篇幅实际上都在介绍识别带彩色噪点的验证码以及处理selenium的几个小众的问题
环境
Python:Python3
网络:学校内网
request实现
代码比下面的selenium的要短很多,关键是在于:
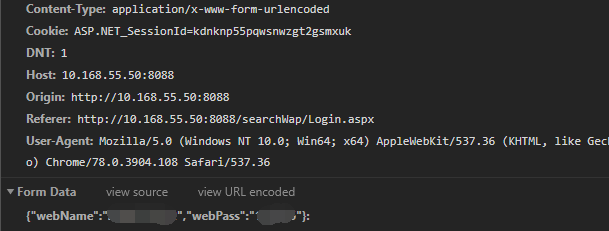
- header里面的
"AjaxPro-Method": "getLoginInput",通过浏览器的检查可以看到 - 比较有趣的是
data=json.dumps(post_data),这个之前也在其他的爬虫程序中见过,但是没有特别注意,其实这里post的数据还是Form Data,但是内部却是Json….一开始确实没注意到
import requests
import json
import re
import time
USERNAME="请输入输入用户名"
PASSWORD=""
login_page = requests.get("http://10.168.55.50:8088/searchWap/Login.aspx")
cookies_login=login_page.cookies
post_data={
"webName":USERNAME,
"webPass":PASSWORD
}
HEADER = {
"AjaxPro-Method": "getLoginInput",
'Host': '10.168.55.50:8088',
'Connection': 'keep-alive',
'Origin': 'http://10.168.55.50:8088'
}
login_result = requests.post("http://10.168.55.50:8088/ajaxpro/SearchWap_Login,App_Web_fghipt60.ashx",data=json.dumps(post_data),cookies=cookies_login, headers = HEADER)
balance_page=requests.get('http://10.168.55.50:8088/searchWap/webFrm/met.aspx',cookies=cookies_login)
pattern_name = re.compile('表名称:(.*?) ',re.S)
name=re.findall(pattern_name,balance_page.text)
pattern_balance = re.compile('剩余量:(.*?) </td>',re.S)
balance=re.findall(pattern_balance,balance_page.text)
ctime=time.ctime()
print(ctime,"%.2f"% float(balance[0]))
如果要做电费的记录的话见需要Linux添加计划任务,见后文
selenium实现
依赖
系统:推荐在Linux环境下使用(比如说WSL),Win下建议通过Scoop来安装Chromedriver
Python库:
import os
import time
from selenium import webdriver
from PIL import Image
import pytesseract
import sys
其中,pytesseract需要下面的Tesseract才能够正常使用
如果是linux平台的话,在纯命令行的情况下(无GUI,如WSL),headless模式可能存在一些问题,可能需要安装xvfb为虚拟GUI,然后再在python中安装pyvirtualdisplay
WSL的话可以在Win10下安装并开启VcXsrv作为代替
注:因为个人的电脑更新Win10到了1903之后,WSL使用Chrome的headless模式会崩溃,所以对Linux平台暂时用Docker作为替代,后文有构建镜像用的Dockerfile
Tesseract
Tesseract 是一个 OCR(Optical Character Recognition,光学字符识别)引擎,能够识别图片中字符
Github 地址:tesseract-ocr/tesseract
Linux:Github上有说明,一般使用系统自带的包管理安装就好,例如:sudo apt install tesseract-ocr
Windows:普通的安装方法比较麻烦(下一节有介绍使用Scoop安装的方法),参考下面的教程设置,主要是环境变量
Windows安装Tesseract-OCR 4.00并配置环境变量
安装完成之后,在命令行键入tesseract得到软件提示说明安装成功
Webdriver
selenium是浏览器测试工具,WebDriver是通过原生浏览器支持或者浏览器扩展来直接控制浏览器,通过安装不同的webdriver来支持不同的浏览器,详情可见:selenium3 浏览器驱动,这里选择的是ChromeDriver,同样Linux推荐用包管理安装apt install chromium-chromedriver,windows推荐用Scoop安装,也可以通过下载对应的exe,放置在.py文件同目录内使用
Dockerfile
构建时需要把代码拷到Dockerfile同目录下,运行的时候挂载记录的文件
FROM ubuntu:latest
MAINTAINER lwz322@qq.com
# 拷贝本地文件到镜像中 efee.sh *.py
COPY ./* /root/
# 在build这个镜像时执行的操作:中文支持
ENV LANG C.UTF-8
# 修改软件源以及安装倚赖和必要的软件
RUN sed -i 's/archive.ubuntu.com/mirrors.ustc.edu.cn/g' /etc/apt/sources.list \
&& apt-get update && mkdir ~/.pip && touch ~/.pip/pip.conf \
&& apt-get install -y python3-pip vim tesseract-ocr chromium-chromedriver screen cron ssh
RUN echo "[global] \nindex-url = https://mirrors.ustc.edu.cn/pypi/web/simple \nformat = columns" > ~/.pip/pip.conf \
&& pip3 install pytesseract lxml prettytable cssselect selenium requests
# 添加cron计划任务
RUN echo "*/30 * * * * /root/efee.sh 2>&1" >> /var/spool/cron/crontabs/root \
&& echo "tessedit_char_whitelist 0123456789QWERTYUIOPASDFGHJKLZXCVBNM" > /usr/share/tesseract-ocr/*/tessdata/configs/DIGIT_CAPS
之后在容器启动时开启cron服务就可以了
Windows下使用Scoop安装软件
按照介绍Scoop的文章的方法安装好Scoop之后,只需要在命令行执行:
scoop install tesseract
scoop install chromedriver
安装完成之后再命令行输入tesseract和chromedriver即可使用,省去了手动添加环境变量
因为Windows的Chrome会自动更新,所以偶尔Chromedriver提示版本不支持的时候使用scoop update chromedriver就好
使用方法
基本的使用就是修改代码中的账户名和密码,然后运行代码即可
注:模拟浏览器的方法运行速度比requests要慢很多,尤其是在启动的时候
分步
模拟浏览器算是爬虫里面最万能的方法了吧,除了性能上要差一点,代码的逻辑和一般的登陆实际操作差不多,这里遇到的主要问题就是验证码的处理以及涉及到文件部分的细节
验证码的问题
这次的验证码是带有彩色噪点背景的图片(ashx or Gif),直接输入到Tesseract是完全无法识别的,所以需要做灰度化以及降噪的处理,处理完之后还是比较好识别的;这里考虑到图片的彩色噪点都是单像素的,故先采取灰度化,再用单个像素的领域去判断该像素是否为噪点,处理之后的图片的识别率还能接受
这里不得不提一下一个没有解决的问题,chromedriver的screenshot在纯Linux命令行下是不能使用的,原因不明,所以只能根据网站生成验证码的规律,打开登陆页面后,再打开一个新的验证码网页,在登陆的时候提交新的验证码和账号密码登陆
Tesseract的识别范围限定
首先是限定OCR的文本为一行
try:
captcha_string = pytesseract.image_to_string(captcha_img, config="--psm 7 DIGITS_CAPS")
except:
captcha_string = pytesseract.image_to_string(captcha_img, config="--psm 7")
配置方面,为了方便运行,这里无论有没有添加限制范围的文件都是可以用的,配置的路径是$TESSDATA/configs,Linux下就是 /usr/share/tesseract-ocr/*/tessdata/configs,新建文件DIGITS_CAPS,内容如下
tessedit_char_whitelist 0123456789QWERTYUIOPASDFGHJKLZXCVBNM
用命令比较快:
echo "tessedit_char_whitelist 0123456789QWERTYUIOPASDFGHJKLZXCVBNM" > /usr/share/tesseract-ocr/*/tessdata/configs/DIGIT_CAPS
headless模式下载文件的问题
用过Chrome的都知道,在打开一些URL的时候Chrome是会自动下载的,然而在headless模式下(命令行模式),打开URL却不能自动下载,后来在网上搜索了很久才找到一条解决的方法
Selenium 如何使用webdriver下载文件(chrome浏览器)
即通过浏览器的控制台来下载,另外就是要指定文件下载目录为脚本文件的路径
alert处理
比如说验证码输入错误了,一般是有弹窗的,如果不处理弹窗,程序就会报错,这里需要在报错时加入一个点击“确认”的操作,之后再刷新
driver.switch_to.alert.accept()
driver.refresh()
后续
之后简化日常的查询了
命令行别名
如果是shell的话设置别名相对方便一点
echo "alias NAME='python3 YOUR_PYTHON_SCRIPT_PATH'">>~/.bashrc
source ~/.bashrc
如果是在Windows下的话,别名貌似不太方便(可以考虑下scoop别名)
用批处理代替就好,把下面的代码保存为.bat后缀的文件,双击即可运行
python YOUR_PYTHON_SCRIPT_PATH
pause
计划任务
这里使用Linux的crontab来添加计划任务(Windows有计划任务,但是PC不常开);SHELL_SCRIPT_PATH是定时执行的shell脚本,比如说每隔一个小时运行一次shell脚本,并把错误重定向到正常的输出中
* */1 * * * SHELL_SCRIPT_PATH 2>&1
如果是运行Python脚本,可以在SHELL_SCRIPT中运行并做重定向
#!/bin/sh
python3 PYTHON_SCRIPT_PATH >> YOUR_LOG_PATH
至于具体的输出格式就看个人的定制了,为了方便看用量和邮件提醒余额,shell脚本如下:
#!/bin/sh
log_file="./xidian_me.log"
[ -f $log_file ] && pre_value=$(tail -1 $log_file | awk '{print $6}')
query_output=$(python3 ./xidian_me_log.py 2>/dev/null)
query_value=$(echo $query_output | awk '{print $6}')
[ $pre_value != $query_value ] || exit 0
[ -n $pre_value ] && useage=`echo $pre_value-$query_value | bc`
echo $query_output $useage >> $log_file
# send balance alert
need_charge=`echo "$query_value < 20" | bc `
[ $need_charge == 1 ] && python3 ./send_email.py
Cron文件:
*/1 4-5/1 * * * /rootx/idian_me.sh 2>&1
*/1 22-23/1 * * * /root/xidian_me.sh 2>&1
注:WSL的Crontab是init进程的子进程,故关闭bash的时候就把WSL的进程都关闭了,据说1803版本之后中关闭 bash.exe 不会再关闭打开的 Linux 进程了,也就是说不需要再在后台维持一个 bash.exe
邮件提醒
宿舍欠电费停电是一件让人非常恼火的事情,因为停电的时间点和恢复供电时间没有一个定数,学校的能源系统有这个功能,但是无法正常使用了。这里就可以结合shell的检测,使用Python发提醒邮件,如send_email.py
from email import encoders
from email.header import Header
from email.mime.text import MIMEText
from email.mime.base import MIMEBase
from email.mime.multipart import MIMEMultipart
from email.utils import parseaddr, formataddr
import smtplib
def _format_addr(s):
name, addr = parseaddr(s)
return formataddr((Header(name, 'utf-8').encode(), addr))
def sendmail(main_text, head, annex = False, annex_path = None):
from_addr = '发件邮箱'
password = '发件邮箱密码'
to_addr = '收件邮箱'
smtp_server = '发件邮箱SMTP服务器地址'
msg = MIMEMultipart()
# 邮件正文是 MIMEText:
msg.attach(MIMEText(main_text, 'plain', 'utf-8'))
msg['From'] = _format_addr('Ubuntu <%s>' % from_addr)
msg['To'] = _format_addr('Equation <%s>' % to_addr)
msg['Subject'] = Header(head, 'utf-8').encode()
if annex:
with open(annex_path, 'rb') as f:
mime = MIMEBase('电费记录', 'log', filename='xidian_me.log')
mime.add_header('Content-Disposition', 'attachment', filename='xidian_me.log')
mime.add_header('Content-ID', '<0>')
mime.add_header('X-Attachment-Id', '0')
mime.set_payload(f.read())
encoders.encode_base64(mime)
msg.attach(mime)
server = smtplib.SMTP(smtp_server, 25)
#server.set_debuglevel(1)
server.login(from_addr, password)
server.sendmail(from_addr, [to_addr], msg.as_string())
server.quit()
sendmail("用量附件","电费余额提醒",annex = True, annex_path = "./xidian_me.log")