日常记录和写论文的工具的积累,包括好用的OCR工具、数学公式识别工具、还有自己写的小工具
Markdown
简单看下就好,因为本身就很简单
因为排版简洁美观,读起来也更加舒服,
Markdown种类很多 基本语法是相通的 对着教程看下就好
Github Markdown的Guid
西电开源社区的帖子
这个PDF就是从Markdown导出的,平时用来排版文字,代码,数学公式是极为方便的,用来简单的写个作业或者论文初稿也是可以的
数学公式的写法和LaTeX基本相同
试从\int^{+\infty}_0e^{-y^2}{\rm{d}}y=\frac{\sqrt{\pi}}{2}推出L(x)=\int^{+\infty}_0e^{-y^2-\frac{c^2}{y^2}}\rm{d}x=\frac{\sqrt{\pi}}{2}e^{-2c}
渲染出来就是 \(试从\int^{+\infty}_0e^{-y^2}{\rm{d}}y=\frac{\sqrt{\pi}}{2}推出L(x)=\int^{+\infty}_0e^{-y^2-\frac{c^2}{y^2}}\rm{d}x=\frac{\sqrt{\pi}}{2}e^{-2c}\)
$\LaTeX$
因为之前有提到LaTeX 所以就简单地推荐一本书还有软件
电子书《一份不太简短的LATEX 2ε 介绍》(或《103 分钟了解LATEX2ε 》),Github提供了电子书以及书的源码,一两天可以快速扫读一遍,之后再在使用中积累经验
对于数学公式,可以使用的速查: Wiki Help:数学公式
Typora
官网,大概在20年前后,Beta之后需要付费了
Typora是一个支持实时渲染的,跨平台的Markdown编辑器,平时拿来写点公式特别方便
设置建议使用把markdown文件引用的图片统一保存到本地的相对路径,方便备份和跨设备,也可以使用图床(说不定哪天就没了),较新的版本也支持图片使用PicGo服务
PicGo
Molunerfinn/PicGo 又是一个相见恨晚的软件,支持从剪贴板复制图片,自动上传并输出Markdown引用URL的格式,对于使用Markdown写博客的人,可以使用Github+picGo搭建图床
OCR
Optical Character Recognition,也就是文字识别或者图像转文字,比如常见字体的验证码识别可以用开源的tesseract,但是对于其他比较复杂的使用情况还是要用专业的工具
ABBYY FineReader
软件官网:ABBYY FineReader 12 功能十分强大的一个付费软件,操纵也比较简单
比如可以识别PDF论文里面的表格到Excel,免去手动抄写/复制数据出错,效果如下:
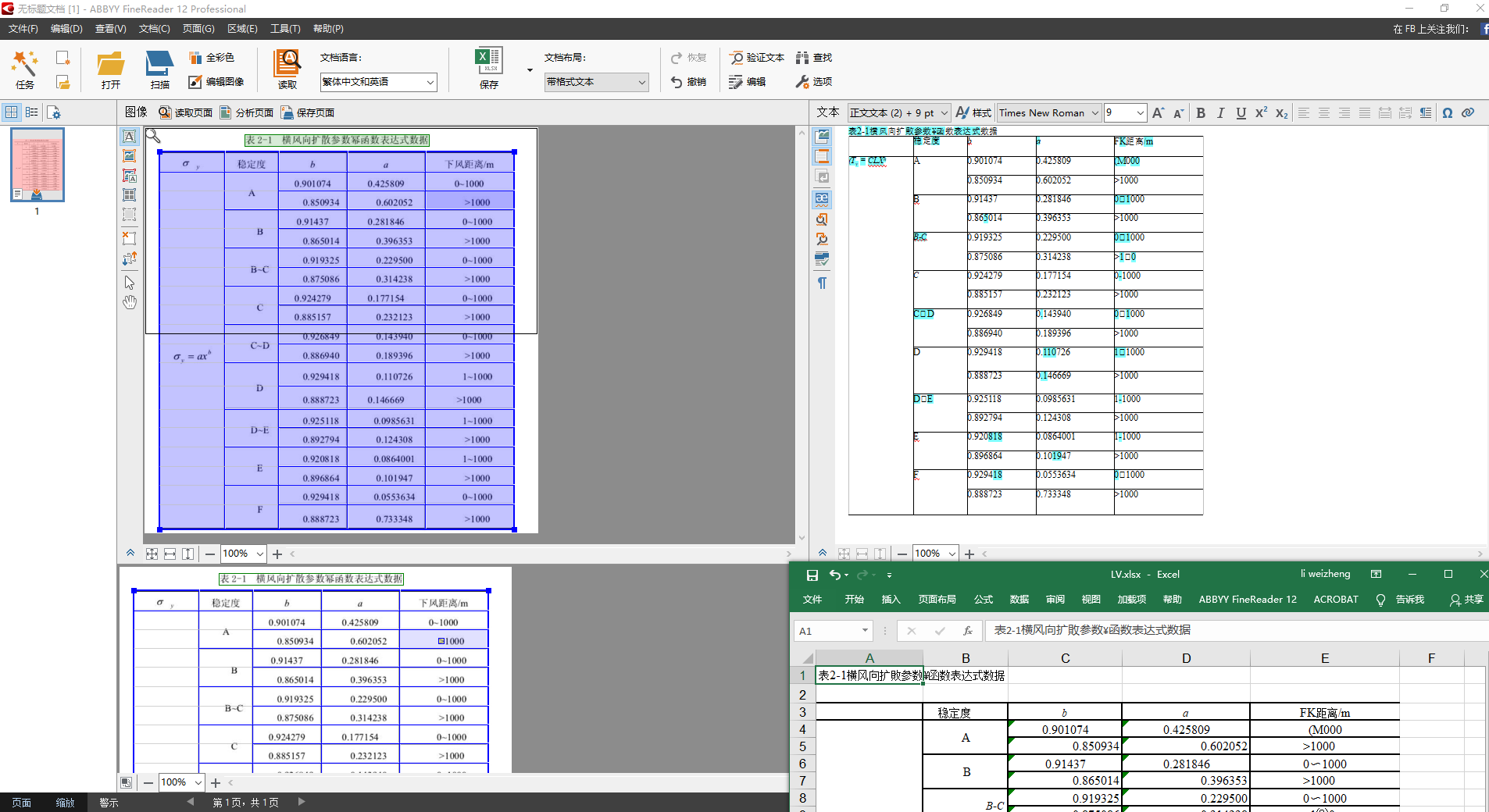
如果是需要截图识别并将数据复制到LaTeX排版的表格的话,可以用下文的Excel2LaTeX复制数据,下文的Mathpix在更新后也具备了一定的表格识别能力
这家公司还有其他的OCR产品,部分也提供了试用
这里顺带说下 为什么有中国的官网不用
一些软件为了强化对盗版的控制,会选择在中国找代理商,然而由于国内外环境的差异,有些软件可能不会提供试用版甚至有中国定制版….
平时搜索一些东西的时候建议用Google…
可以找Adobe的中国代理,以及Flash中国版的新闻看看
Mathpix
$\LaTeX$ 数学公式OCR软件,也可以识别手写,平时主要是识别论文里面的复杂公式,这样能够节省写代码的时间
Update:Mathpix对普通的注册用户一个月只能免费用50次,再用就得5刀一月,暂时的一个解决办法是用信用卡开API:一个月可以免费用1000次,在之后一直到10万次都是0.004美元/次
具体开启流程可以参考:GLGJSSY的知乎专栏,工具可以用blaisewang/img2latex-mathpix
也可以根据官方的API文档按照喜好写,自己就写了一个简易的版本,在WSL下的效果如图:
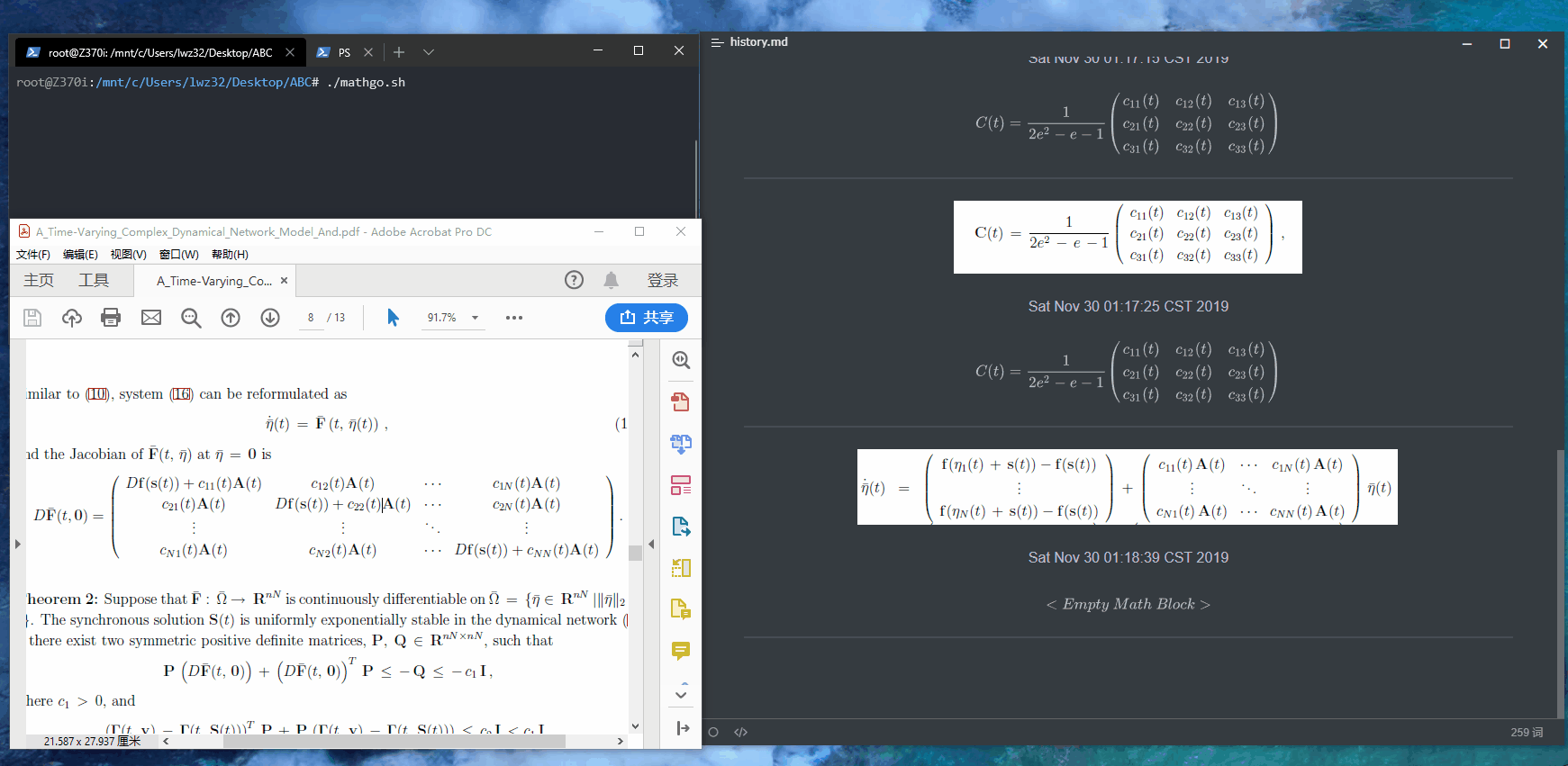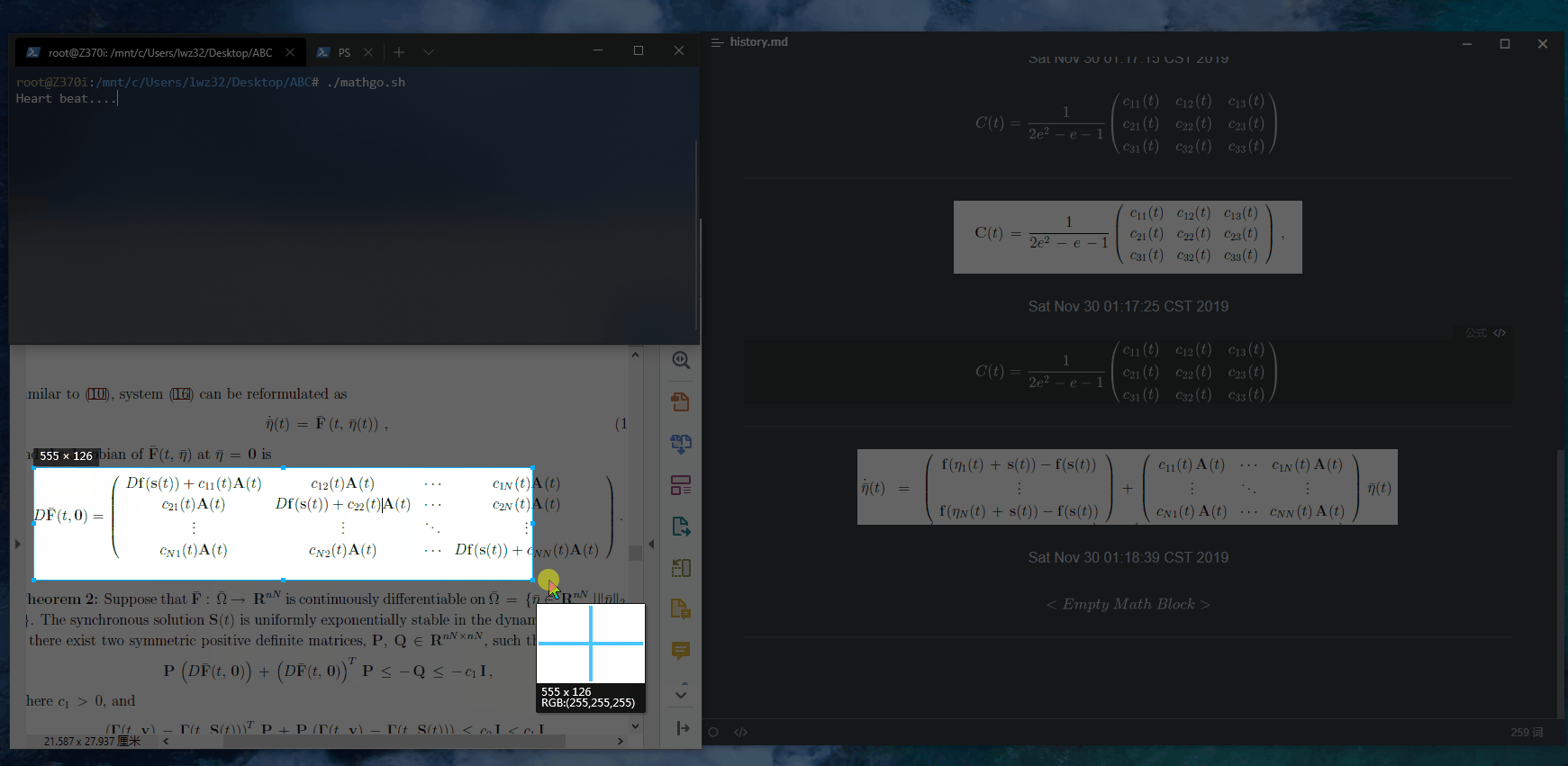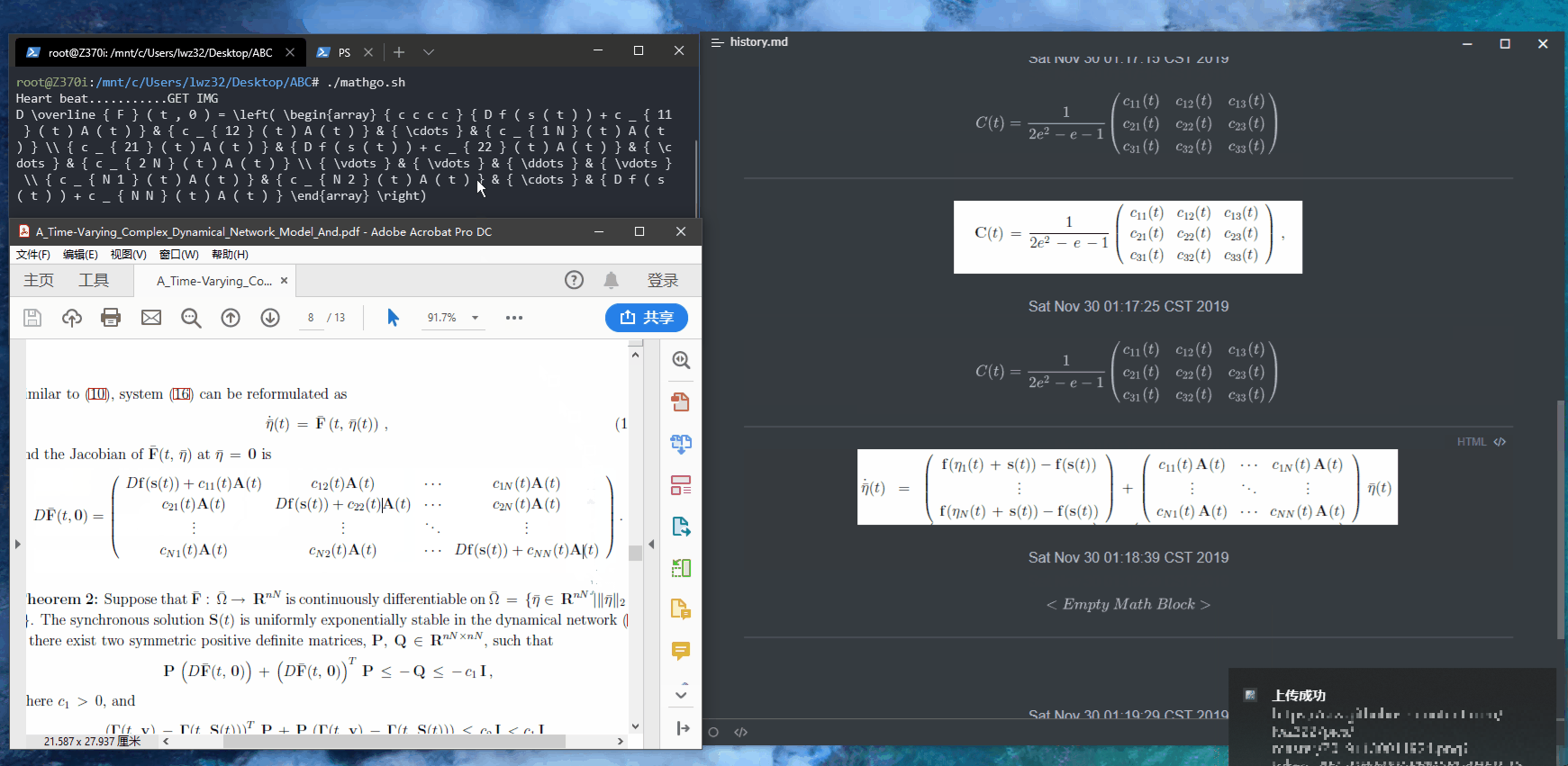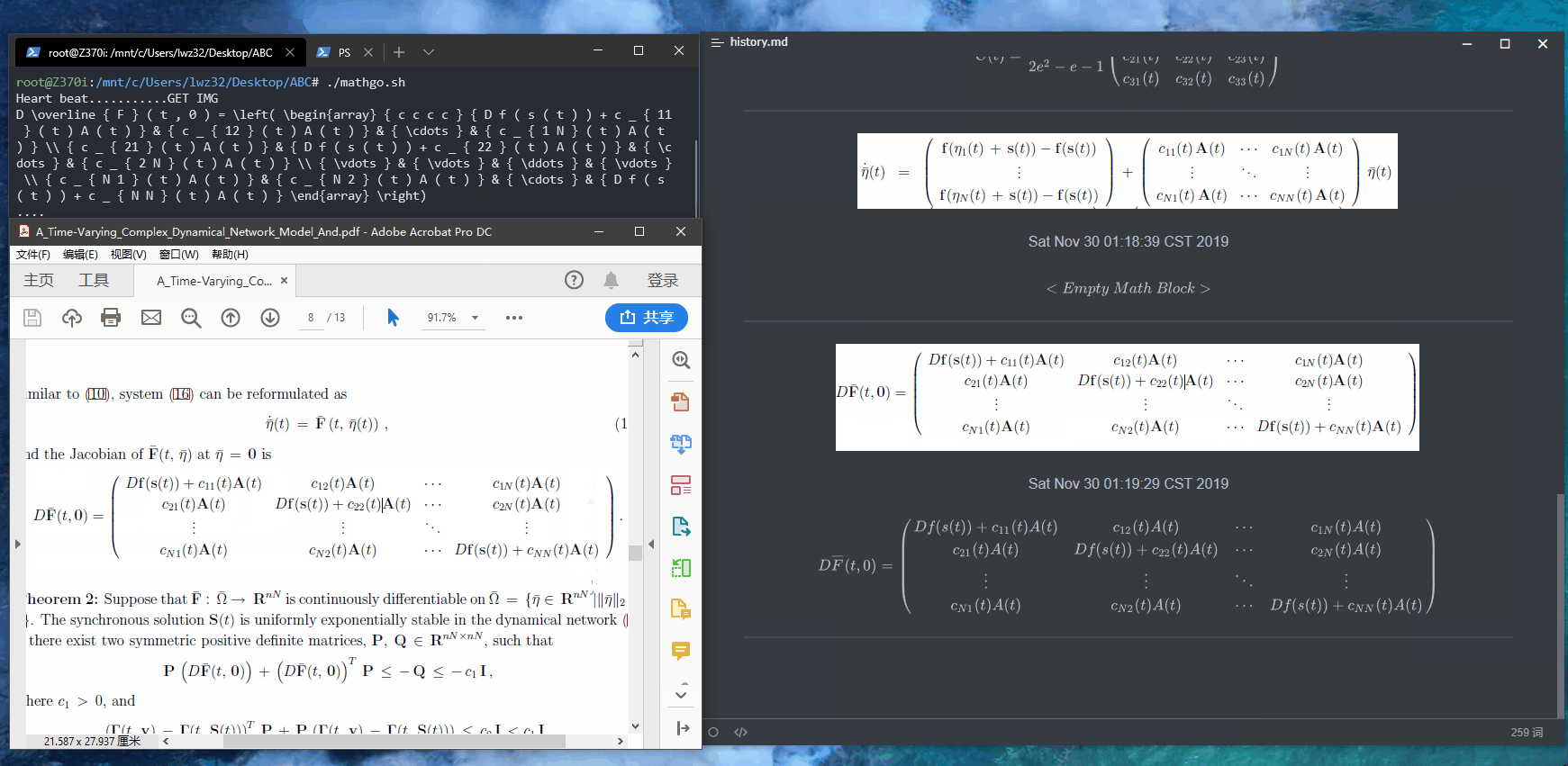
手写有时候会有些小问题,检查之后修改一下就好

美中不足的,在大陆可能因为连不上服务器而不能用,远程IP都是AWS的服务器(18年用cports看到的)

Excel2LaTeX
把Excel表格快速转换成LaTeX代码
CLI Tools
命令行工具…因为之前写了简略的文档,这里就复制过来了,根据个人的需求来做的,价值不大
Cnki2Bib
一个运行在MacOS下的命令行小工具,之前既然提到了这里还是给出说明吧,作者也提到,其实没多大用,因为同样的论文用Google学术或者百度学术搜一下再直接按照BibTex格式导出就好了
WSL移植
因为周围的同学主要还是在Windows环境下,平时最多也只是用下WSL(windows的Linux子系统),所以就简单的移植了下

一些准备
-
WSL子系统
-
命令行剪贴板 xclip (或者xsel)
-
Windows下的X windows Server : vcxsrv
因为WSL使用剪贴板需要display
-
Ruby环境以及chinese_pinyin库
使用方式
-
复制 知网上的GB格式的引文条目
-
在WSL命令行执行脚本
此时转换完成的引文格式已经到了剪贴板上
-
粘贴已经转换的Bibtex格式即可
存在的问题
对比来看的话,应该还是需要按照需求来看吧,比如说作者名字需不需要转拼音之类的,如果常用cnki的话,小问题还是有不少的,这里没有呈现的,一个是第一行,博士论文就不是article了(GB格式信息有限),所以这个只是粗略的转换,之后可能还需要细改
#!/bin/bash
# 首先从剪切板当中读取数据
string=$(xclip -selection clipboard -o)
echo $string
# 当剪切板中的数据不符合要求时,直接退出脚本
size=${#string}
if [ $size -lt 1 ] && [ $size -gt 200 ]; then
echo "字符串为空或过长,疑似数据有误!";echo
exit 1
fi
echo size is $size
# 新建函数用以快速切割字符串
# 需要提供原始字符串以及相应的切割符号
# 事实上可以使用cut,sed等高级工具的,但是我不会啊,回头再加以改善吧
splitString(){
rawstring=$1
tempstr=${rawstring//./ }
arr=($tempstr)
}
# 开始切割字符串
splitString $string .
# 计算数组元素个数
num=${#arr[*]}
echo $num
if [ $num -ne 3 ] && [ $num -ne 4 ]; then
echo "剪贴板内数据无法被切割为三组或者是四组,请检查数据";echo
exit 1
fi
# 开始处理第一组数据,作者的名字以及不需要的[1]
tempstr=${arr[0]}
tempstr=${tempstr#\[*\]}
tempstr=${tempstr//,/ }
temparr=($tempstr)
tempnum=${#temparr[*]}
if [ $tempnum -eq 1 ]; then
author=$tempstr
else
for((i=0;i<tempnum;i++))
do
if [ $i -eq 0 ]; then
author=${temparr[$i]}
else
author=$author" and "${temparr[$i]}
fi
done
fi
# 开始处理第二段数据,去掉最后的[J]直接就可以用啦
tempstr=${arr[1]}
title=${tempstr%\[*\]}
# 开始处理第三段数据
# 首先给出期刊名字
tempstr=${arr[2]}
tempstr=${tempstr//,/ }
temparr=($tempstr)
journal=${temparr[0]}
# 开始抽离出后续的内容
# 首先是页码
tempstr=${temparr[1]}
tempstr=${tempstr//:/ }
temparr=($tempstr)
pages=${temparr[1]}
# 开始抽出期刊时间与相应的卷数
tempstr=${temparr[0]}
tempstr=${tempstr//\(/ }
tempstr=${tempstr//\)/}
temparr=($tempstr)
year=${temparr[0]}
number=${temparr[1]}
# 这里准备输出的模板
# 使用ch2py来输出作者首字母的拼音
# https://blog.csdn.net/hanchaohao2012/article/details/53678319
# sudo gem install chinese_pinyin
key=$(ch2py ${author:0:1})
result="@article{$key$year,\n \
author={$author},\n \
title={$title},\n \
journal={$journal},\n \
year={$year},\n \
number={$number},\n \
pages={$pages},\n \
language={chinese},\n\
}"
# 将最后的结果输出到剪贴板中
Wiki2LaTeX
也是随手写的把维基复制下来的公式图片批量转换为LaTeX代码的一行bash命令
sed -i -e 's:!\[:\n$$\n:g' -e 's:]([^ ]*):\n$$:g' filename
用法:复制公式的图片,可以是多个,复制到Typora(Typora会自动解析出网络图片的网址),之后以Markdown文件为输入运行脚本就可以得到多个公式的行间公式的LaTeX代码
脚本最大的作用还是在于批处理吧,如果公式不多的话
直接在维基的网页用检查工具也是可以的,只需要找到图片对应的源代码
<img src="https://wikimedia.org/api/rest_v1/media/math/render/svg/37638fc8a691764fe848ef7723088dccc7d6bb21" class="mwe-math-fallback-image-inline" aria-hidden="true" style="vertical-align: -3.171ex; width:28.425ex; height:7.509ex;" alt="{\displaystyle \operatorname {Var} (X)=\left(\sum _{i=1}^{n}p_{i}x_{i}^{2}\right)-\mu ^{2},}">
中的alt之后的部分alt="{\displaystyle \operatorname {Var} (X)=\left(\sum _{i=1}^{n}p_{i}x_{i}^{2}\right)-\mu ^{2},}"就是LaTeX的源代码,至于原理:
alt 属性是一个必需的属性,它规定在图像无法显示时的替代文本。
假设由于下列原因用户无法查看图像,alt 属性可以为图像提供替代的信息:
- 网速太慢
- src 属性中的错误
- 浏览器禁用图像
- 用户使用的是屏幕阅读器
我们强烈推荐您在文档的每个图像中都使用这个属性。这样即使图像无法显示,用户还是可以看到关于丢失了什么东西的一些信息。而且对于残疾人来说,alt 属性通常是他们了解图像内容的唯一方式。